
International
ADVANCED AND APPLIED SCIENCES
EISSN: 2313-3724, Print ISSN: 2313-626X
Frequency: 12
![]()
Volume 12, Issue 4 (April 2025), Pages: 136-145

----------------------------------------------
Original Research Paper
Optimizing n-gram lengths for cross-linguistic text classification: A comparative analysis of English and Arabic morphosyntactic structures
Author(s):
Affiliation(s):
Management Information System Department, University of Buraimi, Al Buraimi, Oman
Full text

* Corresponding Author.
 Corresponding author's ORCID profile: https://orcid.org/0000-0001-5867-3986
Corresponding author's ORCID profile: https://orcid.org/0000-0001-5867-3986
Digital Object Identifier (DOI)
https://doi.org/10.21833/ijaas.2025.04.015
Abstract
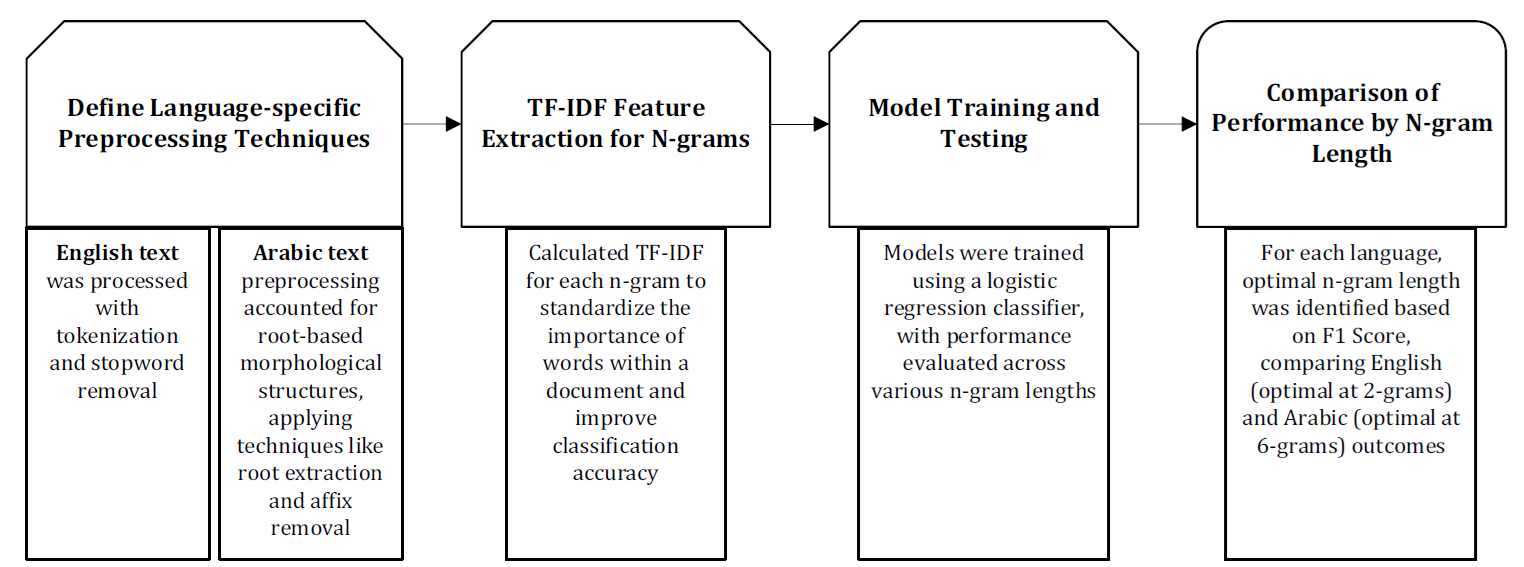
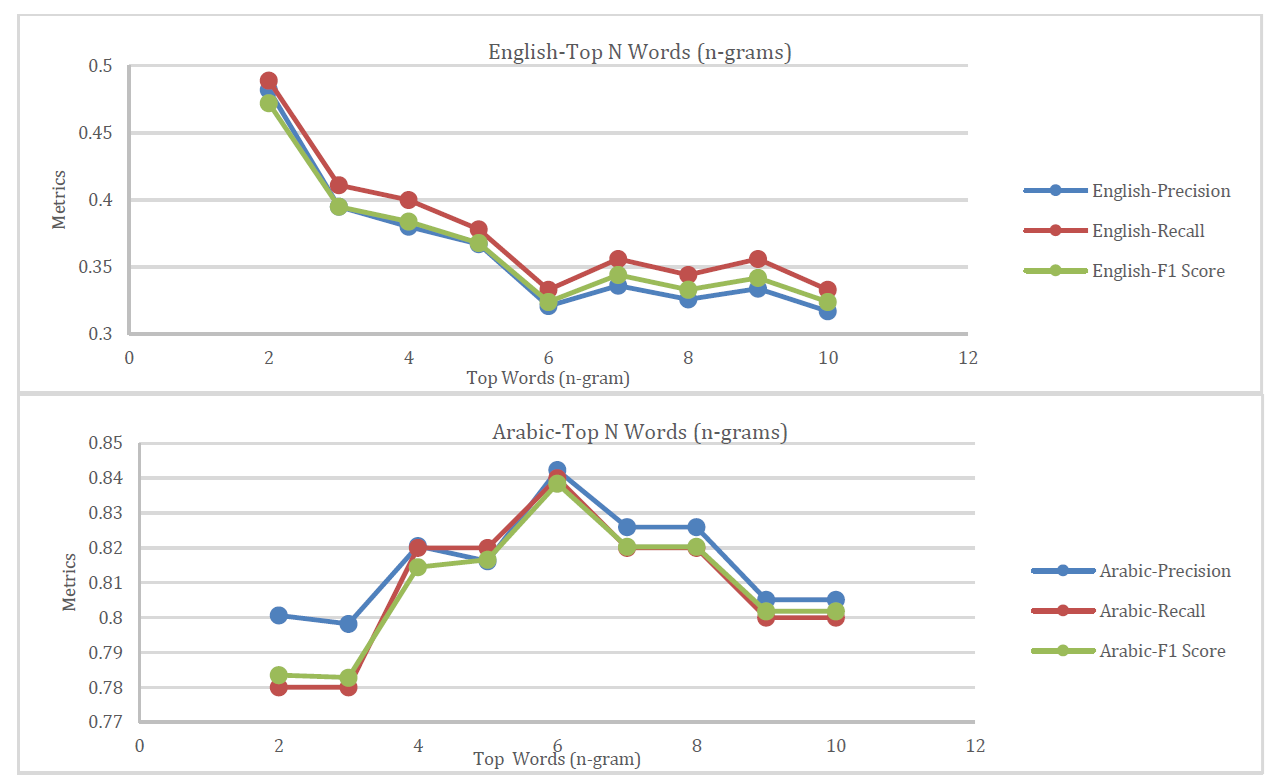
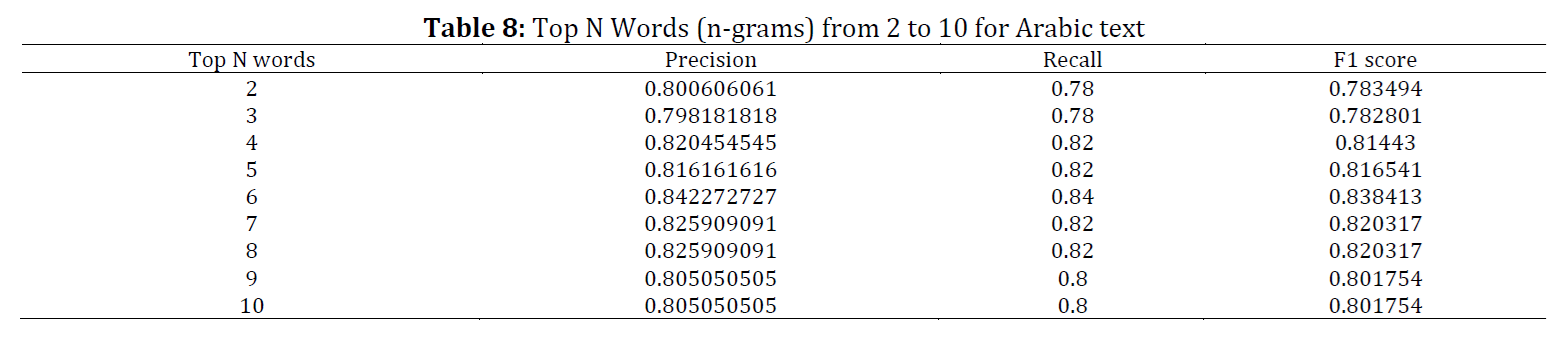
This paper investigates the impact of n-gram length on text classification in English and Arabic, two languages with different writing systems. The study aims to examine how language characteristics influence the optimal n-gram length for text classification. The English dataset comprises 4,450 articles categorized into business, technology, entertainment, sports, and politics, with 2,225 records used for training and 2,225 for testing. The Arabic dataset includes 5,000 randomly selected documents from a total of 111,728 documents. The findings indicate that for English text classification, 2-grams provide the best performance with a precision of 0.482, recall of 0.489, and F1 score of 0.472. In contrast, Arabic text classification achieves optimal performance with 6-grams, reaching an F1 score close to 0.85. These results highlight that language-dependent morphological and syntactic features can significantly affect the performance of n-gram-based models. This study provides valuable insights for enhancing language-sensitive text classification techniques, particularly for accurately and efficiently categorizing documents in different languages.
© 2025 The Authors. Published by IASE.
This is an
Keywords
N-gram length, Text classification, English language, Arabic language, Morphological features
Article history
Received 15 November 2024, Received in revised form 24 March 2025, Accepted 23 April 2025
Acknowledgment
The author would also like to acknowledge the support of the University of Buraimi to thank the university for the financial assistance, resources, facilities, and academic assistance largely used in the completion of this work.
Compliance with ethical standards
Conflict of interest: The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Citation:
Shannaq B (2025). Optimizing n-gram lengths for cross-linguistic text classification: A comparative analysis of English and Arabic morphosyntactic structures. International Journal of Advanced and Applied Sciences, 12(4): 136-145
Figures
Fig. 1 Fig. 2 Fig. 3 Fig. 4 Fig. 5
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Tables
Table 1 Table 2 Table 3 Table 4 Table 5 Table 6 Table 7 Table 8
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
----------------------------------------------
References (30)
- Al Katat S, Zaki C, Hazimeh H, Bitar I, Angarita R, and Trojman L (2024). Natural language processing for Arabic sentiment analysis: A systematic literature review. IEEE Transactions on Big Data, 10(5): 576-594. https://doi.org/10.1109/TBDATA.2024.3366083 [Google Scholar]
- Alhazmi A, Mahmud R, Idris N, Abo MEM, and Eke C (2024). A systematic literature review of hate speech identification on Arabic Twitter data: Research challenges and future directions. PeerJ Computer Science, 10: e1966. https://doi.org/10.7717/peerj-cs.1966 [Google Scholar] PMid:38660217 PMCid:PMC11041964
- AlMahmoud RH and Hammo BH (2024). SEWAR: A corpus-based N-gram approach for extracting semantically-related words from Arabic medical corpus. Expert Systems with Applications, 238: 121767. https://doi.org/10.1016/j.eswa.2023.121767 [Google Scholar]
- Alomari D and Ahmad I (2024). Exploring character trigrams for robust Arabic text classification: A comparative analysis in the face of vocabulary expansion and misspelled words. IEEE Access, 12: 57103-57116. https://doi.org/10.1109/ACCESS.2024.3390048 [Google Scholar]
- Al-Shalif SA, Senan N, Saeed F, Ghaban W, Ibrahim N, Aamir M, and Sharif W (2024). A systematic literature review on meta-heuristic based feature selection techniques for text classification. PeerJ Computer Science, 10: e2084. https://doi.org/10.7717/peerj-cs.2084 [Google Scholar] PMid:38983195 PMCid:PMC11232610
- Alshammary H, Ibrahim MF, and Hussein HA (2024). Evaluating the impact of feature extraction techniques on Arabic reviews classification. InfoTech Spectrum: Iraqi Journal of Data Science, 1(1): 42-54. https://doi.org/10.51173/ijds.v1i1.10 [Google Scholar]
- de la Hoz-Ruiz A, Howard E, and Hijón-Neira R (2024). The enhancement of statistical literacy: A cross-institutional study using data analysis and text mining to identify statistical issues in the transition to university education. Information, 15(9): 567. https://doi.org/10.3390/info15090567 [Google Scholar]
- Fazal F and Farook C (2024). A machine learning approach for depression detection in Sinhala-English code-mixed. International Journal on Advances in ICT for Emerging Regions, 17(3): 102-112. https://doi.org/10.4038/icter.v17i3.7282 [Google Scholar]
- Gurgurov D, Bäumel T, and Anikina T (2024). Multilingual large language models and curse of multilinguality. Arxiv Preprint Arxiv:2406.10602. https://doi.org/10.48550/arXiv.2406.10602 [Google Scholar]
- Jacques de Sousa L, Poças Martins J, Sanhudo L, and Santos Baptista J (2024). Automation of text document classification in the budgeting phase of the Construction process: A systematic literature review. Construction Innovation, 24(7): 292-318. https://doi.org/10.1108/CI-12-2022-0315 [Google Scholar]
- Khurana D, Koli A, Khatter K, and Singh S (2023). Natural language processing: State of the art, current trends and challenges. Multimedia Tools and Applications, 82(3): 3713-3744. https://doi.org/10.1007/s11042-022-13428-4 [Google Scholar] PMid:35855771 PMCid:PMC9281254
- Kumar R and Thirumaran S (2024). Enhancing automatic English word analysis and prediction using higher-order n-gram models. In the International Conference on Science Technology Engineering and Management, IEEE, Coimbatore, India: 1-7. https://doi.org/10.1109/ICSTEM61137.2024.10560953 [Google Scholar]
- Masadeh M, Chola C, and Muaad AY (2024). Investigating the impact of preprocessing techniques and representation models on Arabic text classification using machine learning. International Journal of Advanced Computer Science and Applications, 15(1): 1115-1123. https://doi.org/10.14569/IJACSA.2024.01501110 [Google Scholar]
- Miah MSU, Kabir MM, Sarwar TB, Safran M, Alfarhood S, and Mridha MF (2024). A multimodal approach to cross-lingual sentiment analysis with ensemble of transformer and LLM. Scientific Reports, 14: 9603. https://doi.org/10.1038/s41598-024-60210-7 [Google Scholar] PMid:38671064 PMCid:PMC11053029
- Moniri S, Schlosser T, and Kowerko D (2024). Investigating the challenges and opportunities in Persian language information retrieval through standardized data collections and deep learning. Computers, 13(8): 212. https://doi.org/10.3390/computers13080212 [Google Scholar]
- Ribeiro M, Malcorra B, Mota NB, Wilkens R, Villavicencio A, Hubner LC, and Rennó-Costa C (2024). A methodology for explainable large language models with integrated gradients and linguistic analysis in text classification. Arxiv Preprint Arxiv:2410.00250. https://doi.org/10.48550/arXiv.2410.00250 [Google Scholar]
- Sabty C (2024). Computational approaches to Arabic-English code-switching. Arxiv Preprint Arxiv:2410.13318. https://doi.org/10.48550/arXiv.2410.13318 [Google Scholar]
- Setiawan Y, Maulidevi NU, and Surendro K (2024). The optimization of n-gram feature extraction based on term occurrence for cyberbullying classification. Data Science Journal, 23: 31. https://doi.org/10.5334/dsj-2024-031 [Google Scholar]
- Shannaq B (2024a). Improving security in intelligent systems: How effective are machine learning models with TF-IDF vectorization for password-based user classification. Journal of Theoretical and Applied Information Technology, 102(22): 8340-8355. [Google Scholar]
- Shannaq B (2024b). Unveiling the nexus: Exploring TAM components influencing professors' satisfaction with smartphone integration in lectures: A case study from Oman. Technology, Education, Management, Informatics Journal, 13(3): 2365-2375. https://doi.org/10.18421/TEM133-63 [Google Scholar]
- Shannaq B and Al-Zeidi A (2024). Intelligent information system: Leveraging AI and machine learning for university course registration and academic performance enhancement in educational systems. In: Hamdan A (Eds.), Achieving sustainable business through AI, technology education and computer science: Teaching technology and business sustainability: 51-65. Volume 2, Springer, Cham, Switzerland. https://doi.org/10.1007/978-3-031-71213-5_5 [Google Scholar]
- Shannaq B, Al Shamsi I, and Majeed SNA (2019). Management information system for predicting quantity martials. Technology, Education, Management, Informatics Journal, 8(4): 1143-1149. https://doi.org/10.18421/TEM84-06 [Google Scholar]
- Shannaq B, Ali O, Maqbali SA, and Al-Zeidi A (2024). Advancing user classification models: A comparative analysis of machine learning approaches to enhance faculty password policies at the University of Buraimi. Journal of Infrastructure, Policy and Development, 8(13): 9311. https://doi.org/10.24294/jipd9311 [Google Scholar]
- Sindane T and Marivate V (2024). From n-grams to pre-trained multilingual models for language identification. Arxiv Preprint Arxiv:2410.08728. https://doi.org/10.48550/arXiv.2410.08728 [Google Scholar]
- Sun G, Cheng Y, Zhang Z, Tong X, and Chai T (2024). Text classification with improved word embedding and adaptive segmentation. Expert Systems with Applications, 238: 121852. https://doi.org/10.1016/j.eswa.2023.121852 [Google Scholar]
- Svete A, Borenstein N, Zhou M, Augenstein I, and Cotterell R (2024). Can transformers learn n-gram language models? In the 2024 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Miami, USA: 9851–9867. https://doi.org/10.18653/v1/2024.emnlp-main.550 [Google Scholar]
- Taha K, Yoo PD, Yeun C, Homouz D, and Taha A (2024). A comprehensive survey of text classification techniques and their research applications: Observational and experimental insights. Computer Science Review, 54: 100664. https://doi.org/10.1016/j.cosrev.2024.100664 [Google Scholar]
- Wahdan A, Al-Emran M, and Shaalan K (2024). A systematic review of Arabic text classification: Areas, applications, and future directions. Soft Computing, 28(2): 1545-1566. https://doi.org/10.1007/s00500-023-08384-6 [Google Scholar]
- Yokoyama Y (2024). 4-gram applied to English Q&A statements to obtain factor scores. In the 16 th IIAI International Congress on Advanced Applied Informatics (IIAI-AAI), IEEE, Takamatsu, Japan: 9-14. https://doi.org/10.1109/IIAI-AAI63651.2024.00011 [Google Scholar] PMid:39015444 PMCid:PMC11247237
- Yusuf A, Sarlan A, Danyaro KU, Rahman ASB, and Abdullahi M (2024). Sentiment analysis in low-resource settings: A comprehensive review of approaches, languages, and data sources. IEEE Access, 12: 66883-66909. https://doi.org/10.1109/ACCESS.2024.3398635 [Google Scholar]