
International
ADVANCED AND APPLIED SCIENCES
EISSN: 2313-3724, Print ISSN: 2313-626X
Frequency: 12
![]()
Volume 10, Issue 3 (March 2023), Pages: 189-195

----------------------------------------------
Original Research Paper
Bootstrap approach for clustering method with applications
Author(s):
Sulafah M. Saleh Binhimd, Zakiah I. Kalantan *
Affiliation(s):
Department of Statistics, King Abdulaziz University, Jeddah, Saudi Arabia

* Corresponding Author.
 Corresponding author's ORCID profile: https://orcid.org/0000-0002-7040-5623
Corresponding author's ORCID profile: https://orcid.org/0000-0002-7040-5623
Digital Object Identifier:
https://doi.org/10.21833/ijaas.2023.03.023
Abstract:
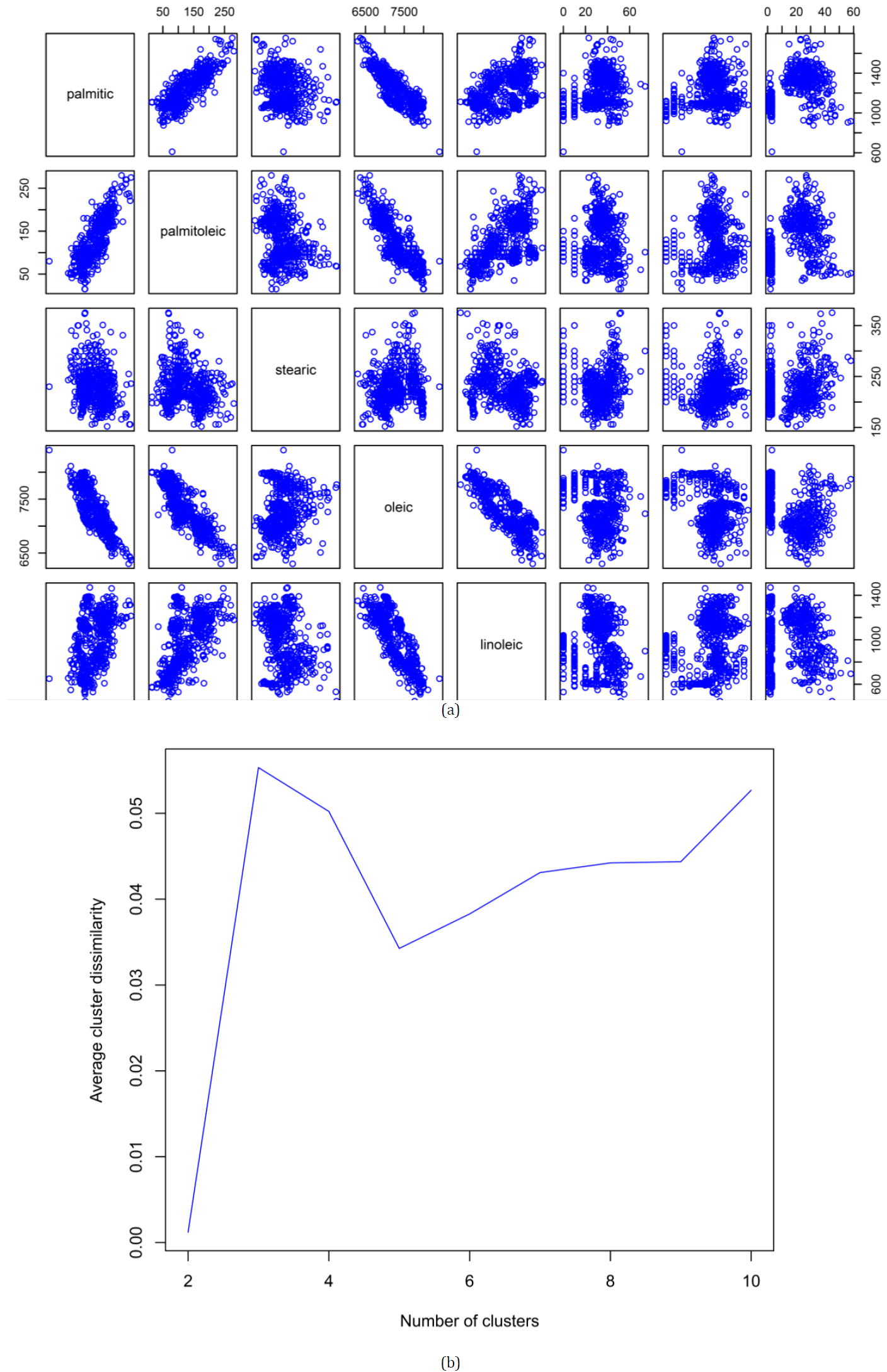
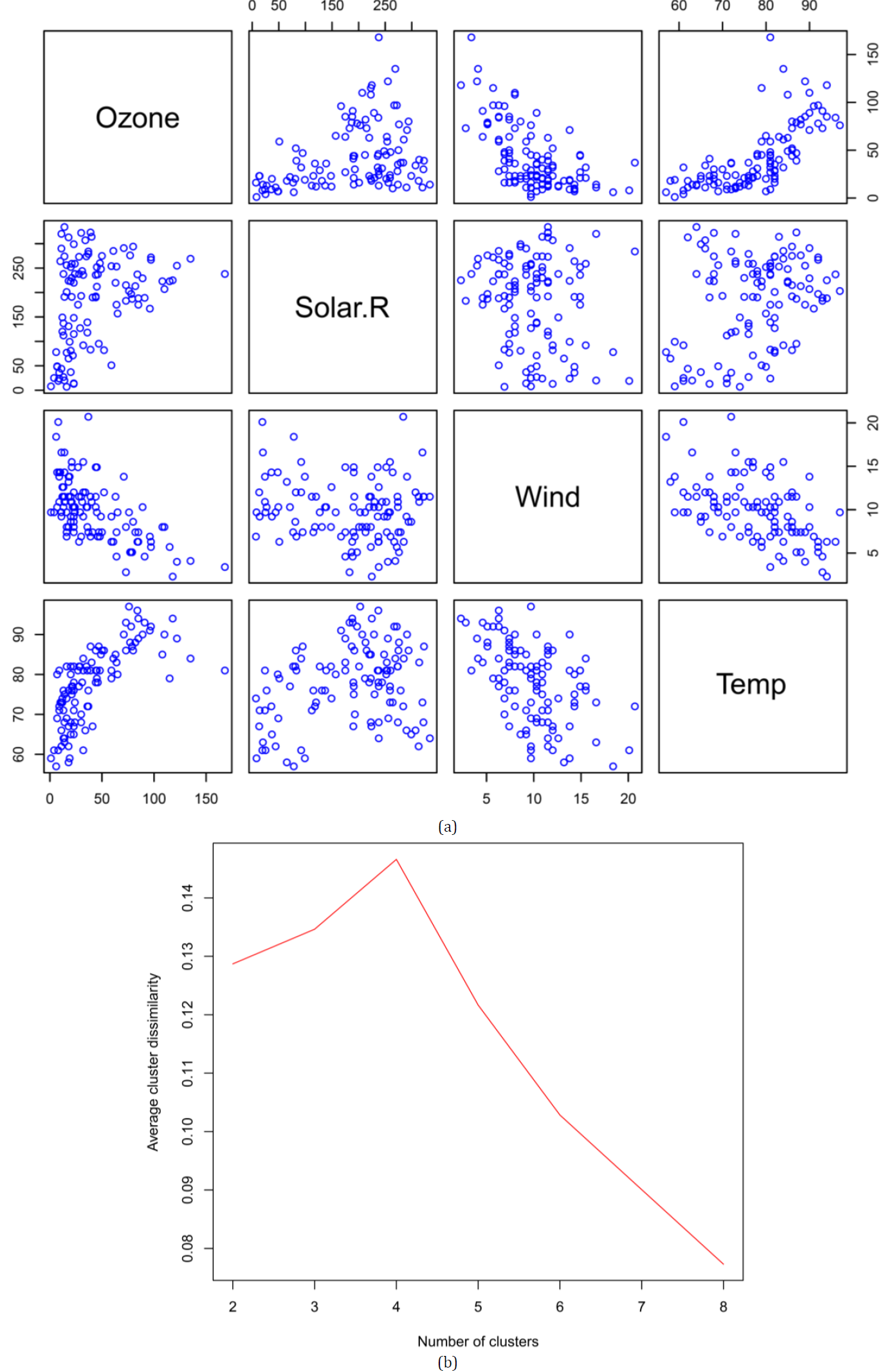
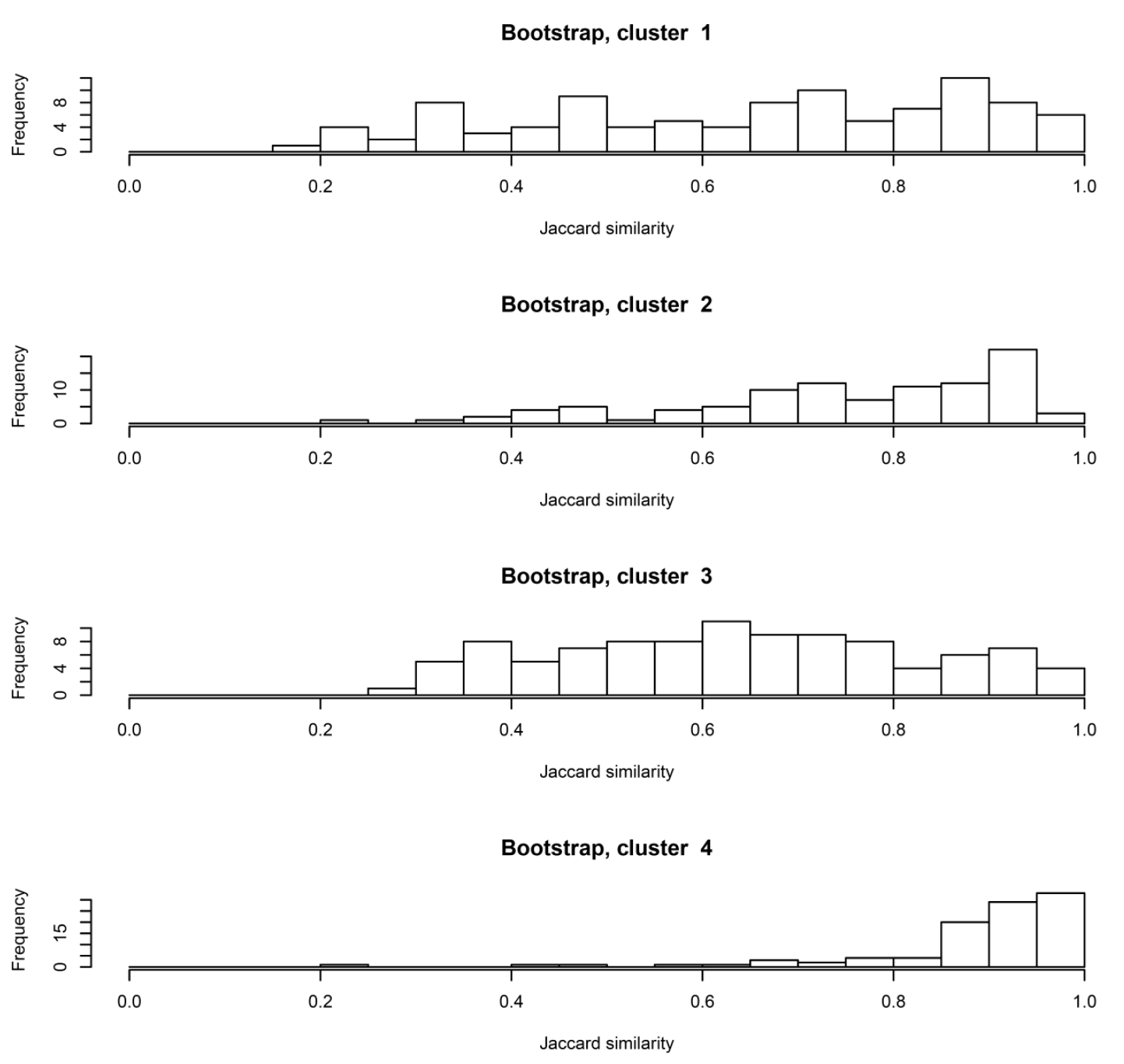
Discovering patterns of big data is an important step to actionable insights data. The clustering method is used to identify the data pattern by splitting the data set into clusters with associated variables. Various research works proposed a bootstrap method for clustering the array data but there is a weak view of statistical or theoretical results and measures of the model consistency or stability. The purpose of this paper is to assess model stability and cluster consistency of the K-number of clusters by using bootstrap sampling patterns with replacement. In addition, we present a reasonable number of clusters via bootstrap methods and study the significance of the K-number of clusters for the original data set by looking at the value of the K-number that provides the most stable clusters. Practically, bootstrap is used to measure the accuracy of estimation and analyze the stability of the outcomes of cluster methods. We discuss the performance of suggestion clusters through running examples. We measure the stability of clusters through bootstrap. A simulation study is presented in order to illustrate the methods of inference discussed and examine the satisfactory performance of the proposed distributions.
© 2022 The Authors. Published by IASE.
This is an
Keywords: Bootstrap method, K-means method, Cluster method, Parametric and semi-parametric methods
Article History: Received 28 June 2022, Received in revised form 24 November 2022, Accepted 26 December 2022
Acknowledgment
No Acknowledgment.
Compliance with ethical standards
Conflict of interest: The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Citation:
Binhimd SMS and Kalantan ZI (2023). Bootstrap approach for clustering method with applications. International Journal of Advanced and Applied Sciences, 10(3): 189-195
Figures
{kind=link}
{kind=link}
{kind=link}
Tables
No Table
----------------------------------------------
References (22)
- Ben-Hur A, Elisseeff A, and Guyon I (2001). A stability based method for discovering structure in clustered data. In: Russ B Altman, A Keith Dunker, Lawrence Hunter, Kevin Lauderdale, and Teri E Klein (Eds.), Biocomputing 2002: 6-17. World Scientific, Kauai, USA. https://doi.org/10.1142/9789812799623_0002 [Google Scholar]
- Cheng G, Yu Z, and Huang JZ (2013). The cluster bootstrap consistency in generalized estimating equations. Journal of Multivariate Analysis, 115: 33-47. https://doi.org/10.1016/j.jmva.2012.09.003 [Google Scholar]
- Efron B (1992). Bootstrap methods: Another look at the jackknife. In: Kotz S and Johnson NL (Eds.), Breakthroughs in statistics: 569-593. Springer, New York, USA. https://doi.org/10.1007/978-1-4612-4380-9_41 [Google Scholar]
- Fang Y and Wang J (2012). Selection of the number of clusters via the bootstrap method. Computational Statistics and Data Analysis, 56(3): 468-477. https://doi.org/10.1016/j.csda.2011.09.003 [Google Scholar]
- Field CA and Welsh AH (2007). Bootstrapping clustered data. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 69(3): 369-390. https://doi.org/10.1111/j.1467-9868.2007.00593.x [Google Scholar]
- Hartigan J (1975). Clustering algorithms. Wiley, New York, USA. [Google Scholar]
- Hennig C (2007). Cluster-wise assessment of cluster stability. Computational Statistics and Data Analysis, 52(1): 258-271. https://doi.org/10.1016/j.csda.2006.11.025 [Google Scholar]
- Jaki T, Su TL, Kim M, and Van Horn ML (2018). An evaluation of the bootstrap for model validation in mixture models. Communications in Statistics-Simulation and Computation, 47(4): 1028-1038. https://doi.org/10.1080/03610918.2017.1303726 [Google Scholar] PMid:30533972 PMCid:PMC6284826
- Jhun M (1990). Bootstrapping k-means clustering. Journal of the Japanese Society of Computational Statistics, 3(1): 1-14. https://doi.org/10.5183/jjscs1988.3.1 [Google Scholar]
- Kalantan ZI (2019). Implementing correlation dimension: K-means clustering via correlation dimension. In the 3rd International Conference on Computing, Mathematics and Statistics, Springer, Reims, France: 359-366. https://doi.org/10.1007/978-981-13-7279-7_44 [Google Scholar]
- Kaufman L and Rousseeuw PJ (2009). Finding groups in data: An introduction to cluster analysis. John Wiley and Sons, New York, USA. [Google Scholar]
- Kerr MK and Churchill GA (2001). Bootstrapping cluster analysis: Assessing the reliability of conclusions from microarray experiments. Proceedings of the National Academy of Sciences, 98(16): 8961-8965. https://doi.org/10.1073/pnas.161273698 [Google Scholar] PMid:11470909 PMCid:PMC55356
- Krzanowski WJ and Lai YT (1988). A criterion for determining the number of groups in a data set using sum-of-squares clustering. Biometrics, 44(1): 23-34. https://doi.org/10.2307/2531893 [Google Scholar]
- Lange T, Roth V, Braun ML, and Buhmann JM (2004). Stability-based validation of clustering solutions. Neural Computation, 16(6): 1299-1323. https://doi.org/10.1162/089976604773717621 [Google Scholar] PMid:15130251
- McCullagh P (2000). Resampling and exchangeable arrays. Bernoulli, 6(2): 285-301. https://doi.org/10.2307/3318577 [Google Scholar]
- Naganathan H, Chong WO, and Chen X (2016). Building energy modeling (BEM) using clustering algorithms and semi-supervised machine learning approaches. Automation in Construction, 72: 187-194. https://doi.org/10.1016/j.autcon.2016.08.002 [Google Scholar]
- Steinley D (2008). Stability analysis in k‐means clustering. British Journal of Mathematical and Statistical Psychology, 61(2): 255-273. https://doi.org/10.1348/000711007X184849 [Google Scholar] PMid:17535479
- Sugar CA and James GM (2003). Finding the number of clusters in a dataset: An information-theoretic approach. Journal of the American Statistical Association, 98(463): 750-763. https://doi.org/10.1198/016214503000000666 [Google Scholar]
- Tibshirani R, Walther G, and Hastie T (2001). Estimating the number of clusters in a data set via the gap statistic. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 63(2): 411-423. https://doi.org/10.1111/1467-9868.00293 [Google Scholar]
- Tibshirani RJ and Efron B (1993). An introduction to the bootstrap. Chapman and Hall, New York, USA. [Google Scholar]
- Wang J (2010). Consistent selection of the number of clusters via crossvalidation. Biometrika, 97(4): 893-904. https://doi.org/10.1093/biomet/asq061 [Google Scholar]
- Yaqoob I, Hashem IA, Gani A, Mokhtar S, Ahmed E, Anuar NB, and Vasilakos AV (2016). Big data: From beginning to future. International Journal of Information Management, 36(6): 1231-1247. https://doi.org/10.1016/j.ijinfomgt.2016.07.009 [Google Scholar]