
International
ADVANCED AND APPLIED SCIENCES
EISSN: 2313-3724, Print ISSN: 2313-626X
Frequency: 12
![]()
Volume 8, Issue 2 (February 2021), Pages: 77-84

----------------------------------------------
Original Research Paper
Title: Content analytics based on random forest classification technique: An empirical evaluation using online news dataset
Author(s): Puteri N. E. Nohuddin 1, *, Wan M. U. Noormanshah 1, Zuraini Zainol 2
Affiliation(s):
1Institute of IR4.0, National University of Malaysia, Bangi, Malaysia
2Department of Computer Science, Faculty of Science and Defence Technology, National Defence University of Malaysia, Kuala Lumpur, Malaysia

* Corresponding Author.
 Corresponding author's ORCID profile: https://orcid.org/0000-0003-0627-5630
Corresponding author's ORCID profile: https://orcid.org/0000-0003-0627-5630
Digital Object Identifier:
https://doi.org/10.21833/ijaas.2021.02.011
Abstract:
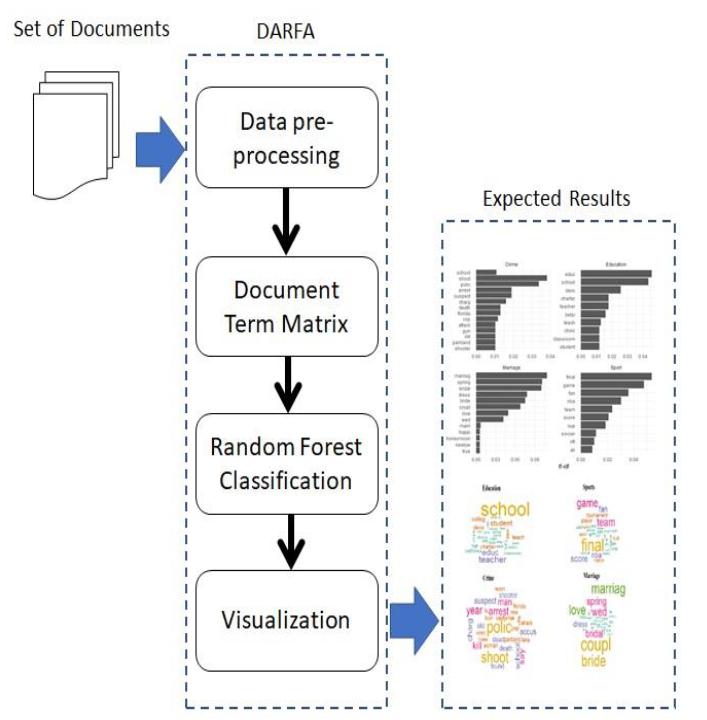
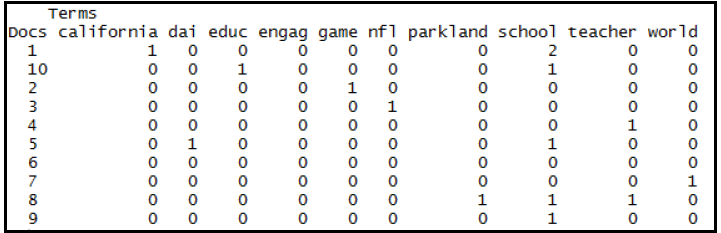
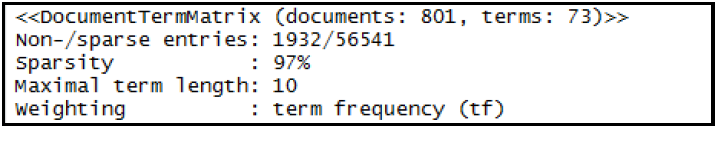
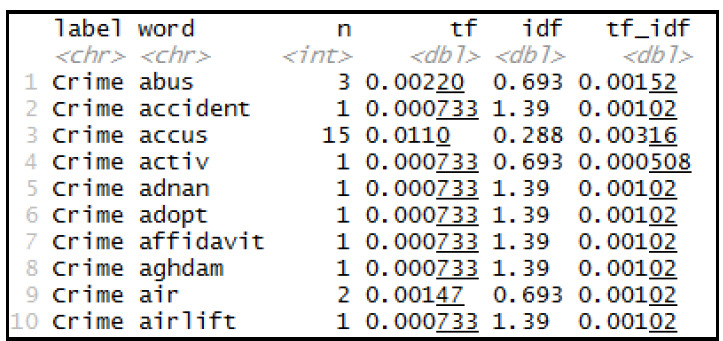
In this paper, a study is established for exploiting a document classification technique for categorizing a set of random online documents. The technique is aimed to assign one or more classes or categories to a document, making it easier to manage and sort. This paper describes an experiment on the proposed method for classifying documents effectively using the decision tree technique. The proposed research framework is a Document Analysis based on the Random Forest Algorithm (DARFA). The proposed framework consists of 5 components, which are (i) Document dataset, (ii) Data Preprocessing, (iii) Document Term Matrix, (iv) Random Forest classification, and (v) Visualization. The proposed classification method can analyze the content of document datasets and classifies documents according to the text content. The proposed framework use algorithms that include TF-IDF and Random Forest algorithm. The outcome of this study benefits as an enhancement to document management procedures like managing documents in daily business operations, consolidating inventory systems, organizing files in databases, and categorizing document folders.
© 2020 The Authors. Published by IASE.
This is an
Keywords: Classification, Random forest, Document term matrix, Term frequency–inversed document, Frequency
Article History: Received 21 June 2020, Received in revised form 1 October 2020, Accepted 7 October 2020
Acknowledgment:
No Acknowledgment.
Compliance with ethical standards
Conflict of interest: The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Citation:
Nohuddin PNE, Noormanshah WMU, and Zainol Z (2021). Content analytics based on random forest classification technique: An empirical evaluation using online news dataset. International Journal of Advanced and Applied Sciences, 8(2): 77-84
Figures
Fig. 1 Fig. 2 Fig. 3 Fig. 4 Fig. 5 Fig. 6 Fig. 7 Fig. 8
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Tables
{kind=link}
----------------------------------------------
References (21)
- Amin A, Al-Obeidat F, Shah B, Adnan A, Loo J, and Anwar S (2019). Customer churn prediction in telecommunication industry using data certainty. Journal of Business Research, 94: 290-301. https://doi.org/10.1016/j.jbusres.2018.03.003 [Google Scholar]
- Caigny AD, Coussement K, and De Bock KW (2018). A new hybrid classification algorithm for customer churn prediction based on logistic regression and decision trees. European Journal of Operational Research, 269(2): 760-772. https://doi.org/10.1016/j.ejor.2018.02.009 [Google Scholar]
- Dabiri S and Heaslip K (2018). Inferring transportation modes from GPS trajectories using a convolutional neural network. Transportation Research Part C: Emerging Technologies, 86: 360-371. https://doi.org/10.1016/j.trc.2017.11.021 [Google Scholar]
- Dean J and Ghemawat S (2008). MapReduce: Simplified data processing on large clusters. Communications of the ACM, 51(1): 107-113. https://doi.org/10.1145/1327452.1327492 [Google Scholar]
- Dunham MH (2006). Data mining: Introductory and advanced topics. Pearson Education India, Bengaluru, India. [Google Scholar]
- Felton BR, O’Neil GL, Robertson MM, Fitch GM, and Goodall JL (2019). Using random forest classification and nationally available geospatial data to screen for wetlands over large geographic regions. Water, 11(6): 1158. https://doi.org/10.3390/w11061158 [Google Scholar]
- Fortuna B, Grobelnik M, and Mladenic D (2005). Visualization of text document corpus. Informatica, 29(4): 497–502. [Google Scholar]
- Han J, Pei J, and Kamber M (2011). Data mining: Concepts and techniques. Elsevier, Amsterdam, Netherlands. [Google Scholar]
- Hussain S, Dahan NA, Ba-Alwib FM, and Ribata N (2018). Educational data mining and analysis of students’ academic performance using WEKA. Indonesian Journal of Electrical Engineering and Computer Science, 9(2): 447-459. https://doi.org/10.11591/ijeecs.v9.i2.pp447-459 [Google Scholar]
- Kalra S, Li L, and Tizhoosh HR (2019). Automatic classification of pathology reports using TF-IDF Features. arXiv:1903.07406. Available online at: https://arxiv.org/abs/1903.07406
- Kamarudin ND, Rahayu SB, Zainol Z, Rusli MS, and Ghani KA (2018). Performance comparison of machine learning classifiers on aircraft databases. Defence Science and Technology Technical Bulletin, 11(2): 154-169. [Google Scholar]
- Kumar PM, Lokesh S, Varatharajan R, Babu GC, and Parthasarathy P (2018). Cloud and IoT based disease prediction and diagnosis system for healthcare using Fuzzy neural classifier. Future Generation Computer Systems, 86: 527-534. https://doi.org/10.1016/j.future.2018.04.036 [Google Scholar]
- Markel J and Bayless AJ (2019). Performance of random forest machine learning algorithms in binary supernovae classification. arXiv:1907.00088. Available online at: https://arxiv.org/abs/1907.00088
- Nohuddin P, Zainol Z, Lee ASH, Nordin I, and Yusoff Z (2018). A case study in knowledge acquisition for logistic cargo distribution data mining framework. International Journal of Advanced and Applied Sciences, 5(1): 8-14. https://doi.org/10.21833/ijaas.2018.01.002 [Google Scholar]
- Priyadarshini MG (2018). Decision tree algorithms for diagnosis of cardiac disease treatment. International Journal of Computer Science and Mobile Computing, 7(7): 138-144. [Google Scholar]
- Rahayu SB, Kamarudin ND, and Zainol Z (2018). Case study of UPNM students performance classification algorithms. Journal Engineering and Technology, 7(4.31): 285-289. [Google Scholar]
- Ramos J (2003). Using TF-IDF to determine word relevance in document queries. In the First instructional Conference on Machine Learning, New Jersey, USA, 242: 133-142. [Google Scholar]
- Zainol Z, Jaymes MT, and Nohuddin PN (2018). VisualUrText: A text analytics tool for unstructured textual data. Journal of Physics: Conference Series, 1018: 012011. https://doi.org/10.1088/1742-6596/1018/1/012011 [Google Scholar]
- Zainol Z, Nohuddin PN, Mohd TA, and Zakaria O (2017). Text analytics of unstructured textual data: A study on military peacekeeping document using R text mining package. In the International Conference on Computing and Informatics, Kuala Lumpur, Malaysia: 1-7. [Google Scholar]
- Zhang W, Yoshida T, and Tang X (2011). A comparative study of TF* IDF, LSI and multi-words for text classification. Expert Systems with Applications, 38(3): 2758-2765. https://doi.org/10.1016/j.eswa.2010.08.066 [Google Scholar]
- Zhou M, Padilla OHM, and Scott JG (2016). Priors for random count matrices derived from a family of negative binomial processes. Journal of the American Statistical Association, 111(515): 1144-1156. https://doi.org/10.1080/01621459.2015.1075407 [Google Scholar]