
International
ADVANCED AND APPLIED SCIENCES
EISSN: 2313-3724, Print ISSN: 2313-626X
Frequency: 12
![]()
Volume 8, Issue 10 (October 2021), Pages: 43-50

----------------------------------------------
Original Research Paper
Title: Improved minimum-minimum roughness algorithm for clustering categorical data
Author(s): Do Si Truong, Nguyen Thanh Tung, Lam Thanh Hien *
Affiliation(s):
Faculty of Information Engineering Technology, Lac Hong University, Bien Hoa, Vietnam

* Corresponding Author.
 Corresponding author's ORCID profile: https://orcid.org/0000-0002-4539-3712
Corresponding author's ORCID profile: https://orcid.org/0000-0002-4539-3712
Digital Object Identifier:
https://doi.org/10.21833/ijaas.2021.10.006
Abstract:
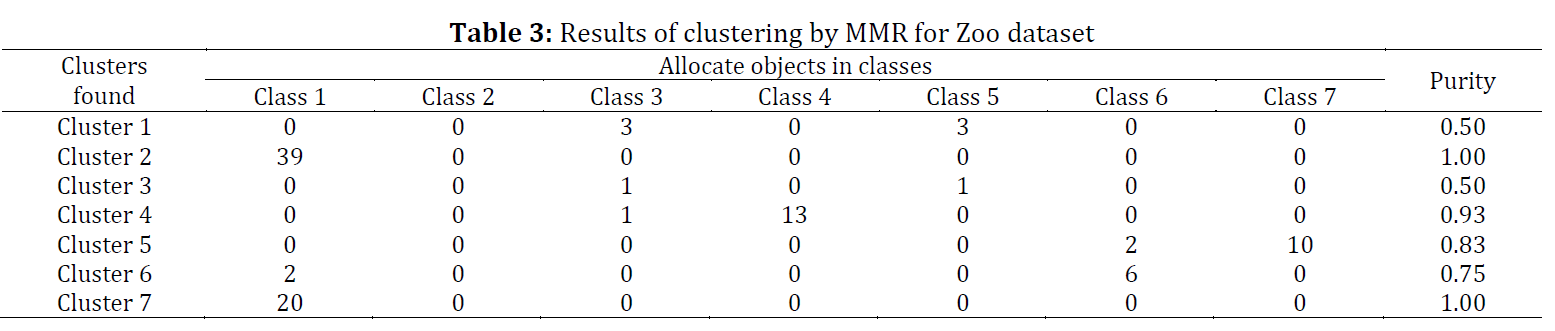
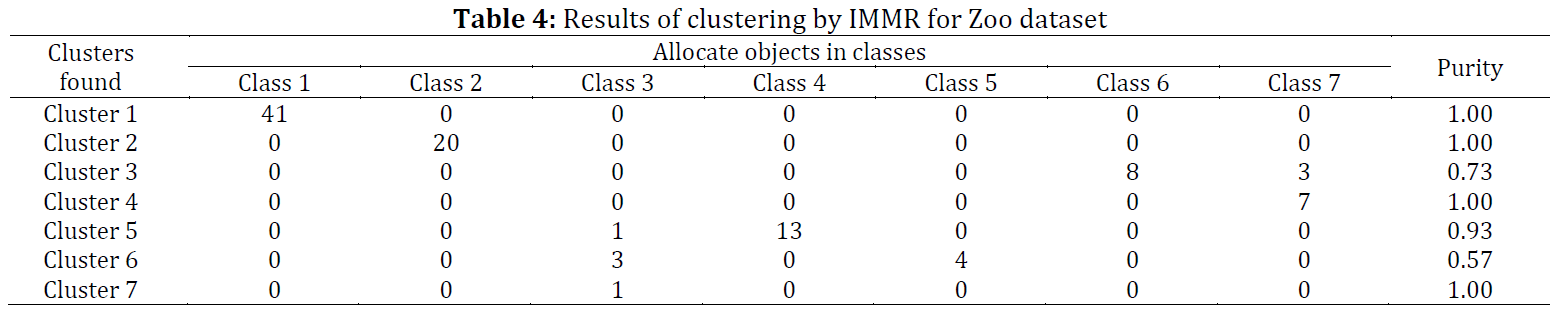
Clustering is a fundamental technique in data mining and machine learning. Recently, many researchers are interested in the problem of clustering categorical data and several new approaches have been proposed. One of the successful and pioneering clustering algorithms is the Minimum-Minimum Roughness algorithm (MMR) which is a top-down hierarchical clustering algorithm and can handle the uncertainty in clustering categorical data. However, MMR tends to choose the category with less value leaf node with more objects, leading to undesirable clustering results. To overcome such shortcomings, this paper proposes an improved version of the MMR algorithm for clustering categorical data, called IMMR (Improved Minimum-Minimum Roughness). Experimental results on actual data sets taken from UCI show that the IMMR algorithm outperforms MMR in clustering categorical data.
© 2021 The Authors. Published by IASE.
This is an
Keywords: Data mining, Categorical data, Rough set theory, Clustering category, IMMR
Article History: Received 17 April 2021, Received in revised form 14 July 2021, Accepted 22 July 2021
Acknowledgment
No Acknowledgment.
Compliance with ethical standards
Conflict of interest: The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Citation:
Truong DS, Tung NT, Hien LT (2021). Improved minimum-minimum roughness algorithm for clustering categorical data. International Journal of Advanced and Applied Sciences, 8(10): 43-50
Figures
{kind=link}
{kind=link}
Tables
Table 1 Table 2 Table 3 Table 4 Table 5 Table 6
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
----------------------------------------------
References (21)
- Bello R and Falcon R (2017). Rough sets in machine learning: A review. In: Wang G, Skowron A, Yao Y, Ślęzak D, and Polkowski L (Eds.), Thriving rough sets: 87-118. Volume 708, Springer, Cham, Switzerland. https://doi.org/10.1007/978-3-319-54966-8_5 [Google Scholar]
- Cao F, Liang J, and Bai L (2009). A new initialization method for categorical data clustering. Expert Systems with Applications, 36(7): 10223-10228. https://doi.org/10.1016/j.eswa.2009.01.060 [Google Scholar]
- Gibson D, Kleinberg J, and Raghavan P (2000). Clustering categorical data: An approach based on dynamical systems. The VLDB Journal, 8(3): 222-236. https://doi.org/10.1007/s007780050005 [Google Scholar]
- Guha S, Rastogi R, and Shim K (2000). ROCK: A robust clustering algorithm for categorical attributes. Information Systems, 25(5): 345-366. https://doi.org/10.1016/S0306-4379(00)00022-3 [Google Scholar]
- Han J and Kamber M. (2006). Data mining: Concepts and techniques. 2nd Edition, Morgan Kaufmann Publishers, Burlington, USA. [Google Scholar]
- Hassanein WA and Elmelegy AA (2014). Clustering algorithms for categorical data using concepts of significance and dependence of attributes. European Scientific Journal, 10: 381-400. [Google Scholar]
- Herawan T, Deris MM, and Abawajy JH (2010). A rough set approach for selecting clustering attribute. Knowledge-Based Systems, 23(3): 220-231. https://doi.org/10.1016/j.knosys.2009.12.003 [Google Scholar]
- Huang Z (1998). Extensions to the k-means algorithm for clustering large data sets with categorical values. Data Mining and Knowledge Discovery, 2(3): 283-304. https://doi.org/10.1023/A:1009769707641 [Google Scholar]
- Ienco D, Pensa RG, and Meo R (2012). From context to distance: Learning dissimilarity for categorical data clustering. ACM Transactions on Knowledge Discovery from Data (TKDD), 6(1): 1-25. https://doi.org/10.1145/2133360.2133361 [Google Scholar]
- Jensen R and Shen Q (2008). New approaches to fuzzy-rough feature selection. IEEE Transactions on Fuzzy Systems, 17(4): 824-838. https://doi.org/10.1109/TFUZZ.2008.924209 [Google Scholar]
- Jyoti D. (2013). Clustering categorical data using rough sets: A review. International Journal of Advanced Research in IT and Engineering, 2(12): 30-37. [Google Scholar]
- Khandelwal G and Sharma R (2015). A simple yet fast clustering approach for categorical data. International Journal of Computer Applications, 120: 25-30. https://doi.org/10.5120/21321-4341 [Google Scholar]
- Kim DW, Lee KH, and Lee D (2004). Fuzzy clustering of categorical data using fuzzy centroids. Pattern Recognition Letters, 25(11): 1263-1271. https://doi.org/10.1016/j.patrec.2004.04.004 [Google Scholar]
- Mazlack LJ, He A, and Zhu Y (2000). A rough set approach in choosing partitioning attributes. In the 13th ISCA International Conference on Parallel and Distributed Computing Systems, Las Vegas, USA: 1-6. [Google Scholar]
- McCaffrey J (2013). Data clustering using entropy minimization. Visual Studio Magazine, California, USA. [Google Scholar]
- Mesakar SS and Chaudhari MS (2012). Review paper on data clustering of categorical data. International Journal of Engineering Research and Technology, 1(10): 1-18. [Google Scholar]
- Parmar D, Wu T, and Blackhurst J (2007). MMR: An algorithm for clustering categorical data using rough set theory. Data and Knowledge Engineering, 63(3): 879-893. https://doi.org/10.1016/j.datak.2007.05.005 [Google Scholar]
- Pawlak Z (1991). Rough sets: Theoretical aspects of reasoning about data. Springer Science and Business Media, Berlin, Germany. [Google Scholar]
- Qin H, Ma X, Zain JM, and Herawan T (2012). A novel soft set approach in selecting clustering attribute. Knowledge-Based Systems, 36: 139-145. https://doi.org/10.1016/j.knosys.2012.06.001 [Google Scholar]
- UCI (2013). Machine learning databases. Available online at: https://archive.ics.uci.edu/ml/machine-learning-databases
- Zhang Q, Xie Q, and Wang G (2016). A survey on rough set theory and its applications. CAAI Transactions on Intelligence Technology, 1(4): 323-333. https://doi.org/10.1016/j.trit.2016.11.001 [Google Scholar]