
International
ADVANCED AND APPLIED SCIENCES
EISSN: 2313-3724, Print ISSN: 2313-626X
Frequency: 12
![]()
Volume 8, Issue 10 (October 2021), Pages: 17-25

----------------------------------------------
Original Research Paper
Title: Automatic detection of cyberbullying and threatening in Saudi tweets using machine learning
Author(s): Deema Alghamdi, Rahaf Al-Motery, Reem Alma'abdi, Ohoud Alzamzami *, Amal Babour
Affiliation(s):
Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah, Saudi Arabia

* Corresponding Author.
 Corresponding author's ORCID profile: https://orcid.org/0000-0002-6555-8166
Corresponding author's ORCID profile: https://orcid.org/0000-0002-6555-8166
Digital Object Identifier:
https://doi.org/10.21833/ijaas.2021.10.003
Abstract:
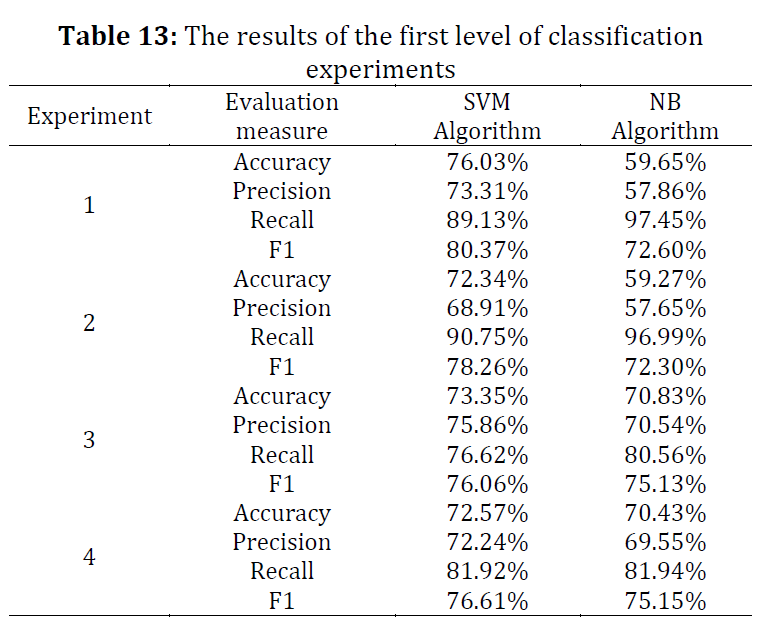
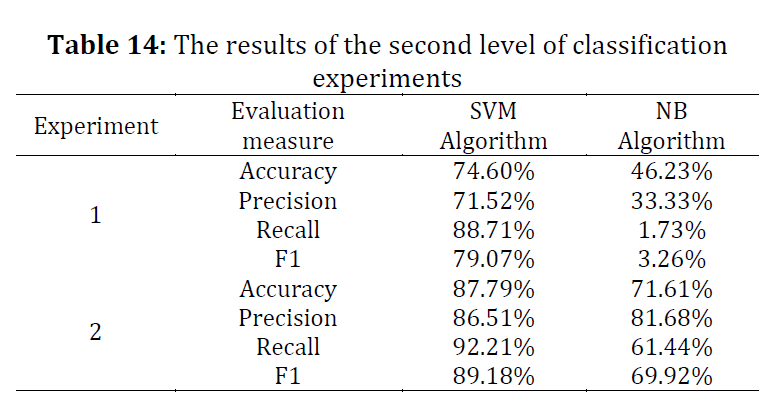
Social media has become a major factor in people's lives, which affects their communication and psychological state. The widespread use of social media has formed new types of violence, such as cyberbullying. Manual detection and reporting of violent texts in social media applications are challenging due to the increasing number of social media users and the huge amounts of generated data. Automatic detection of violent texts is language-dependent, and it requires an efficient detection approach, which considers the unique features and structures of a specific language or dialect. Only a few studies have focused on the automatic detection and classification of violent texts in the Arabic Language. This paper aims to build a two-level classifier model for classifying Arabic violent texts. The first level classifies text into violent and non-violent. The second level classifies violent text into either cyberbullying or threatening. The dataset used to build the classifier models is collected from Twitter, using specific keywords and trending hashtags in Saudi Arabia. Supervised machine learning is used to build two classifier models, using two different algorithms, which are Support Vector Machine (SVM), and Naive Bayes (NB). Both models are trained in different experimental settings of varying the feature extraction method and whether stop-word removal is applied or not. The performances of the proposed SVM-based and NB-based models have been compared. The SVM-based model outperforms the NB-based model with F1 scores of 76.06%, and 89.18%, and accuracy scores of 73.35% and 87.79% for the first and second levels of classification, respectively.
© 2021 The Authors. Published by IASE.
This is an
Keywords: Artificial intelligence, Arabic language, Cyberbullying, Text classification, Machine learning
Article History: Received 26 January 2021, Received in revised form 25 May 2021, Accepted 28 June 2021
Acknowledgment
No Acknowledgment.
Compliance with ethical standards
Conflict of interest: The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Citation:
Alghamdi D, Al-Motery R, Alma'abdi R et al. (2021). Automatic detection of cyberbullying and threatening in Saudi tweets using machine learning. International Journal of Advanced and Applied Sciences, 8(10): 17-25
Figures
{kind=link}
{kind=link}
{kind=link}
Tables
Table 1 Table 2 Table 3 Table 4 Table 5 Table 6 Table 7 Table 8 Table 9 Table 10 Table 11 Table 12 Table 13 Table 14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
----------------------------------------------
References (33)
- Alakrot A, Murray L, and Nikolov NS (2018). Towards accurate detection of offensive language in online communication in Arabic. Procedia Computer Science, 142: 315-320. https://doi.org/10.1016/j.procs.2018.10.491 [Google Scholar]
- AlHarbi BY, AlHarbi MS, AlZahrani NJ, Alsheail MM, Alshobaili JF, and Ibrahim DM (2019). Automatic cyber bullying detection in Arabic social media. International Journal Engineering Research and Technology, 12(12): 2330-2335. [Google Scholar]
- Al-Kabi MN, Al-Qwaqenah AA, Gigieh AH, Alsmearat K, Al-Ayyoub M, and Alsmadi IM (2016). Building a standard dataset for Arabia sentiment analysis: Identifying potential annotation pitfalls. In the IEEE/ACS 13th International Conference of Computer Systems and Applications, IEEE, Agadir, Morocco: 1-6. https://doi.org/10.1109/AICCSA.2016.7945822 [Google Scholar]
- Al-Khalifa H, Magdy W, Darwish K, Elsayed T, and Mubarak H (2020). Proceedings of the 4th workshop on open-source Arabic corpora and processing tools, with a shared task on offensive language detection. In 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France. [Google Scholar]
- Alruily M (2020). Issues of dialectal Saudi twitter corpus. International Arab Journal of Information Technology, 17(3): 367-374. https://doi.org/10.34028/iajit/17/3/10 [Google Scholar]
- Altaher A (2017). Hybrid approach for sentiment analysis of Arabic tweets based on deep learning model and features weighting. International Journal of Advanced and Applied Sciences, 4(8): 43-49. https://doi.org/10.21833/ijaas.2017.08.007 [Google Scholar]
- Biltawi M, Al-Naymat G, and Tedmori S (2017). Arabic sentiment classification: A hybrid approach. In the International Conference on New Trends in Computing Sciences, IEEE, Amman, Jordan: 104-108. https://doi.org/10.1109/ICTCS.2017.24 [Google Scholar]
- Díaz-Torres MJ, Morán-Méndez PA, Villasenor-Pineda L, Montes M, Aguilera J, and Meneses-Lerín L (2020). Automatic detection of offensive language in social media: Defining linguistic criteria to build a Mexican Spanish dataset. In the Second Workshop on Trolling, Aggression and Cyberbullying, European Language Resources Association, Marseille, France: 132-136. [Google Scholar]
- Duwairi RM and Qarqaz I (2014). Arabic sentiment analysis using supervised classification. In the International Conference on Future Internet of Things and Cloud, IEEE, Barcelona, Spain: 579-583. https://doi.org/10.1109/FiCloud.2014.100 [Google Scholar]
- El-Makky N, Nagi K, El-Ebshihy A, Apady E, Hafez O, Mostafa S, and Ibrahim S (2014). Sentiment analysis of colloquial Arabic tweets. In the ASE BigData/SocialInformatics/PASSAT/ BioMedCom 2014 Conference, Harvard University, Cambridge, USA: 1-9. [Google Scholar]
- El-Naggar N, El-Sonbaty Y, and Abou El-Nasr M (2017). Sentiment analysis of modern standard Arabic and Egyptian dialectal Arabic tweets. In the Computing Conference, IEEE, London, UK: 880-887. https://doi.org/10.1109/SAI.2017.8252198 [Google Scholar]
- Gambäck B and Sikdar UK (2017). Using convolutional neural networks to classify hate-speech. In the 1st Workshop on Abusive Language Online, Association for Computational Linguistics, Vancouver, Canada: 85-90. https://doi.org/10.18653/v1/W17-3013 [Google Scholar]
- Haidar B, Chamoun M, and Serhrouchni A (2017). Multilingual cyberbullying detection system: Detecting cyberbullying in Arabic content. In the 1st Cyber Security in Networking Conference, IEEE, Rio de Janeiro, Brazil: 1-8. https://doi.org/10.1109/CSNET.2017.8242005 [Google Scholar]
- Haidar B, Chamoun M, and Yamout F (2016). Cyberbullying detection: A survey on multilingual techniques. In the European Modelling Symposium, IEEE, Pisa, Italy: 165-171. https://doi.org/10.1109/EMS.2016.037 [Google Scholar]
- Han J, Kamber M, and Pei J (2011). Data mining concepts and techniques third edition. The Morgan Kaufmann Series in Data Management Systems, 5(4): 83-124. https://doi.org/10.1016/B978-0-12-381479-1.00003-4 [Google Scholar]
- Husain F (2020). Arabic offensive language detection using machine learning and ensemble machine learning approaches. Available online at: https://arxiv.org/abs/2005.08946
- Ismail R, Omer M, Tabir M, Mahadi N, and Amin I (2018). Sentiment analysis for Arabic dialect using supervised learning. In the International Conference on Computer, Control, Electrical, and Electronics Engineering, IEEE, Khartoum, Sudan: 1-6. https://doi.org/10.1109/ICCCEEE.2018.8515862 [Google Scholar]
- Kumar R, Ojha AK, Malmasi S, and Zampieri M (2018). Benchmarking aggression identification in social media. In the First Workshop on Trolling, Aggression and Cyberbullying, Santa Fe, USA: 1-11. [Google Scholar]
- Mahmud A, Ahmed KZ, and Khan M (2008). Detecting flames and insults in text. In the 6th International Conference on Natural Language Processing, CDAC Pune, Pune, India. [Google Scholar]
- Modha S, Majumder P, and Mandl T (2018). Filtering aggression from the multilingual social media feed. In the 1st Workshop on Trolling, Aggression and Cyberbullying, Santa Fe, USA: 199-207. [Google Scholar]
- Mohaouchane H, Mourhir A, and Nikolov NS (2019). Detecting offensive language on Arabic social media using deep learning. In the 6th International Conference on Social Networks Analysis, Management and Security, IEEE, Granada, Spain: 466-471. https://doi.org/10.1109/SNAMS.2019.8931839 [Google Scholar]
- Mouheb D, Abushamleh MH, Abushamleh MH, Al Aghbari Z, and Kamel I (2019). Real-time detection of cyberbullying in Arabic Twitter streams. In the 10th IFIP International Conference on New Technologies, Mobility and Security, IEEE, Canary Islands, Spain: 1-5. https://doi.org/10.1109/NTMS.2019.8763808 [Google Scholar]
- Mouheb D, Ismail R, Al Qaraghuli S, Al Aghbari Z, and Kamel I (2018). Detection of offensive messages in Arabic social media communications. In the International Conference on Innovations in Information Technology, IEEE, Al Ain, UAE: 24-29. https://doi.org/10.1109/INNOVATIONS.2018.8606030 [Google Scholar]
- Mubarak H, Darwish K, and Magdy W (2017). Abusive language detection on Arabic social media. In the 1st Workshop on Abusive Language Online, Association for Computational Linguistics, Vancouver, Canada: 52-56. https://doi.org/10.18653/v1/W17-3008 [Google Scholar]
- Mubarak H, Rashed A, Darwish K, Samih Y, and Abdelali A (2020). Arabic offensive language on Twitter: Analysis and experiments. Available online at: https://arxiv.org/abs/2004.02192
- Ross B, Rist M, Carbonell G, Cabrera B, Kurowsky N, and Wojatzki M (2017). Measuring the reliability of hate speech annotations: The case of the European refugee crisis. Available online at: https://arxiv.org/abs/1701.08118
- Schneider JM, Roller R, Bourgonje P, Hegele S, and Rehm G (2018). Towards the automatic classification of offensive language and related phenomena in German tweets. In the 14th Conference on Natural Language Processing KONVENS, Viena, Austria: 95-103. [Google Scholar]
- Soliman AB, Eissa K, and El-Beltagy SR (2017). Aravec: A set of Arabic word embedding models for use in Arabic NLP. Procedia Computer Science, 117: 256-265. https://doi.org/10.1016/j.procs.2017.10.117 [Google Scholar]
- Spertus E (1997). Smokey: Automatic recognition of hostile messages. In the 9th Conference on Innovative Application of Artificial Intelligence, Providence, USA: 1058-1065. [Google Scholar]
- Utomo MRA and Sibaroni Y (2019). Text classification of British English and American English using support vector machine. In the 7th International Conference on Information and Communication Technology, IEEE, Kuala Lumpur, Malaysia: 1-6. https://doi.org/10.1109/ICoICT.2019.8835256 [Google Scholar]
- Van Hee C, Lefever E, Verhoeven B, Mennes J, Desmet B, De Pauw G, and Hoste V (2015). Detection and fine-grained classification of cyberbullying events. In the International Conference Recent Advances in Natural Language Processing, Hissar, Bulgaria: 672-680. [Google Scholar]
- Vieira SM, Kaymak U, and Sousa JM (2010). Cohen's kappa coefficient as a performance measure for feature selection. In the International Conference on Fuzzy Systems, IEEE, Barcelona, Spain: 1-8. https://doi.org/10.1109/FUZZY.2010.5584447 [Google Scholar]
- Wiegand M, Siegel M, and Ruppenhofer J (2018). Overview of the germeval 2018 shared task on the identification of offensive language. In the 14th Conference on Natural Language Processing, Austrian Academy of Sciences, Vienna, Austria: 1-10. [Google Scholar]