
International
ADVANCED AND APPLIED SCIENCES
EISSN: 2313-3724, Print ISSN: 2313-626X
Frequency: 12
![]()
Volume 7, Issue 4 (April 2020), Pages: 1-8

----------------------------------------------
Review Paper
Title: Review of feature extraction approaches on biomedical text classification
Author(s): Rozilawati Dollah 1, *, Tiara Izrinda Jafni 1, Haslina Hashim 1, Mohd Shahizan Othman 1, Abd Wahid Rasib 2
Affiliation(s):
1School of Computing, Faculty of Engineering, Universiti Teknologi Malaysia, 81310 Skudai, Johor, Malaysia
2Program of Geoinformation, Faculty of Built Environment and Surveying, Universiti Teknologi Malaysia, 81310 Skudai, Johor, Malaysia

* Corresponding Author.
 Corresponding author's ORCID profile: https://orcid.org/0000-0001-6007-1749
Corresponding author's ORCID profile: https://orcid.org/0000-0001-6007-1749
Digital Object Identifier:
https://doi.org/10.21833/ijaas.2020.04.001
Abstract:
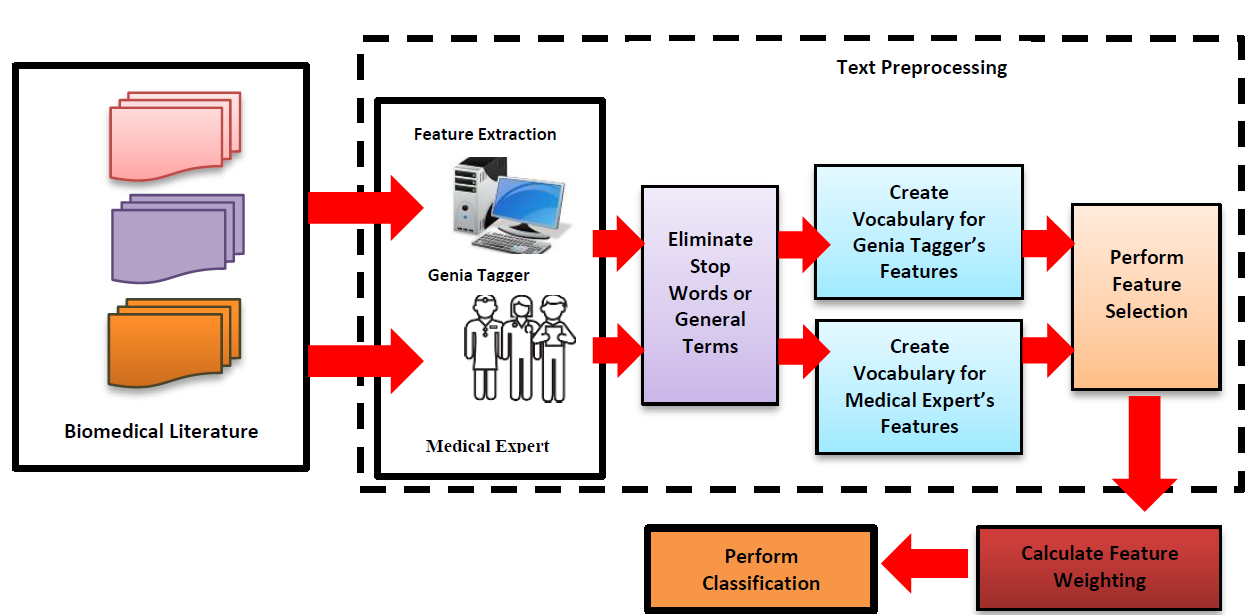
The overcoming volume of online biomedical literature causes congestion of data and difficulties in organizing these documents and also to retrieve the required documents from the database, especially in the Medline database. One of the solutions to surpass the overwhelming of documents is to apply classification. However, each document must be represented by a set of terminology or feature vectors. The identification of terminology or feature from biomedical literature is one of the most important and challenging tasks in text classification. This is due to a large number of new features and entities that appear in the biomedical domain. In addition, combining sets of features from different terminological resources leads to naming conflicts such as homonymous use of names and terminological ambiguities. Therefore, the purpose of this research is to investigate and evaluate the effective ways for extracting the relevant and meaningful features in order to increase the classification accuracy and improve the performance of web searches. Towards this effort, we conduct several classification experiments to evaluate and compare the effectiveness of feature extraction approaches for extracting the relevant and informative features from the biomedical literature. For our experiments, we use two different sets of features, which are a set of features that are extracted using the Genia tagger tool and set of features that are extracted by medical experts from Pusat Perubatan Universiti Kebangsaan Malaysia (PPUKM). The results show the performance of classification using features that are extracted by medical experts outperform the performance of classification using the Genia Tagger tool when applying feature selection method.
© 2020 The Authors. Published by IASE.
This is an
Keywords: Biomedical literature, Feature extraction, Feature selection, Text classification, Text mining
Article History: Received 26 September 2019, Received in revised form 10 January 2020, Accepted 12 January 2020
Acknowledgment:
This study is supported by the Fundamental Research Grant Scheme (FRGS) under the Vote No. 4F559 that sponsored by the Ministry of Higher Education (MOHE) and Research University Grant Scheme (RUG) under the Vote No. 13J94 and 20H01. The authors are greatly obliged to Universiti Teknologi Malaysia (UTM) and Information Engineering and Behavioral Informatics (INFOBEE) Research Group for support and motivation.
Compliance with ethical standards
Conflict of interest: The authors declare that they have no conflict of interest.
Citation:
Dollah R, Jafni TI, and Hashim H et al. (2020). Review of feature extraction approaches on biomedical text classification. International Journal of Advanced and Applied Sciences, 7(4): 1-8
Figures
{kind=link}
{kind=link}
{kind=link}
Tables
{kind=link}
{kind=link}
----------------------------------------------
References (53)
- Al-Angari HM, Kanitz G, Tarantino S, and Cipriani C (2016). Distance and mutual information methods for EMG feature and channel subset selection for classification of hand movements. Biomedical Signal Processing and Control, 27: 24-31. https://doi.org/10.1016/j.bspc.2016.01.011 [Google Scholar]
- Aljaber B, Martinez D, Stokes N, and Bailey J (2011). Improving MeSH classification of biomedical articles using citation contexts. Journal of Biomedical Informatics, 44(5): 881-896. https://doi.org/10.1016/j.jbi.2011.05.007 [Google Scholar] PMid:21683802
- Asdaghi F and Soleimani A (2019). An effective feature selection method for web spam detection. Knowledge-Based Systems, 166: 198-206. https://doi.org/10.1016/j.knosys.2018.12.026 [Google Scholar]
- Azam N and Yao J (2012). Comparison of term frequency and document frequency based feature selection metrics in text categorization. Expert Systems with Applications, 39(5): 4760-4768. https://doi.org/10.1016/j.eswa.2011.09.160 [Google Scholar]
- Banerjee B and Biswas A (2012). On closeness of the Mantel–Haenszel estimator and the profile likelihood based estimator of the common odds ratio from multiple 2×2 tables. Statistics and Probability Letters, 82(11): 1990-1993. https://doi.org/10.1016/j.spl.2012.06.013 [Google Scholar]
- Chandrashekar G and Sahin F (2014). A survey on feature selection methods. Computers and Electrical Engineering, 40(1): 16-28. https://doi.org/10.1016/j.compeleceng.2013.11.024 [Google Scholar]
- Chen D, Müller HM, and Sternberg PW (2006). Automatic document classification of biological literature. BMC Bioinformatics, 7: 370. https://doi.org/10.1186/1471-2105-7-370 [Google Scholar] PMid:16893465 PMCid:PMC1559726
- Chen YT and Chen MC (2011). Using chi-square statistics to measure similarities for text categorization. Expert Systems with Applications, 38(4): 3085-3090. https://doi.org/10.1016/j.eswa.2010.08.100 [Google Scholar]
- Cohen AM (2006). An effective general purpose approach for automated biomedical document classification. In the AMIA Annual Symposium Proceedings, American Medical Informatics Association, Washington D.C., USA: 161-165. [Google Scholar]
- Couto FM, Martins B, and Silva MJ (2004). Classifying biological articles using web resources. In the 2004 ACM Symposium on Applied Computing, ACM, Nicosia, Cyprus: 111-115. https://doi.org/10.1145/967900.967925 [Google Scholar]
- Dadaneh BZ, Markid HY, and Zakerolhosseini A (2016). Unsupervised probabilistic feature selection using ant colony optimization. Expert Systems with Applications, 53: 27-42. https://doi.org/10.1016/j.eswa.2016.01.021 [Google Scholar]
- Ding H, Liang ZY, Guo FB, Huang J, Chen W, and Lin H (2016). Predicting bacteriophage proteins located in host cell with feature selection technique. Computers in Biology and Medicine, 71: 156-161. https://doi.org/10.1016/j.compbiomed.2016.02.012 [Google Scholar] PMid:26945463
- Dollah R and Aono M (2008). Classifying biomedical text abstracts using binary and multi-class support vector machine. In The 22nd Annual Conference of the Japanese Society for Artificial Intelligence, Hokkaido, Japan. [Google Scholar]
- El-Alfy ESM and AlHasan AA (2016). Spam filtering framework for multimodal mobile communication based on dendritic cell algorithm. Future Generation Computer Systems, 64: 98-107. https://doi.org/10.1016/j.future.2016.02.018 [Google Scholar]
- Fang YC, Huang HC, and Juan HF (2008). MeInfoText: Associated gene methylation and cancer information from text mining. BMC Bioinformatics, 9: 22. https://doi.org/10.1186/1471-2105-9-22 [Google Scholar] PMid:18194557 PMCid:PMC2258285
- Fang YC, Lai PT, Dai HJ, and Hsu WL (2011). MeInfoText 2.0: Gene methylation and cancer relation extraction from biomedical literature. BMC Bioinformatics, 12: 471. https://doi.org/10.1186/1471-2105-12-471 [Google Scholar] PMid:22168213 PMCid:PMC3266364
- Feng G, Guo J, Jing BY, and Sun T (2015). Feature subset selection using naive Bayes for text classification. Pattern Recognition Letters, 65: 109-115. https://doi.org/10.1016/j.patrec.2015.07.028 [Google Scholar]
- Ghareb AS, Bakar AA, and Hamdan AR (2016). Hybrid feature selection based on enhanced genetic algorithm for text categorization. Expert Systems with Applications, 49: 31-47. https://doi.org/10.1016/j.eswa.2015.12.004 [Google Scholar]
- Gong L (2018). Application of biomedical text mining. In: Aceves-Fernandez MA (Ed.), Artificial intelligence: Emerging trends and applications: 417-433. Books on Demand, Norderstedt, Germany. https://doi.org/10.5772/intechopen.75924 [Google Scholar]
- Gregory M, Ulmer H, Pfeiffer KP, Lang S, and Strasak AM (2008). A set of SAS macros for calculating and displaying adjusted odds ratios (with confidence intervals) for continuous covariates in logistic B-spline regression models. Computer Methods and Programs in Biomedicine, 92(1): 109-114. https://doi.org/10.1016/j.cmpb.2008.05.004 [Google Scholar] PMid:18603325
- Hernández-Pereira E, Bolón-Canedo V, Sánchez-Maroño N, Álvarez-Estévez D, Moret-Bonillo V, and Alonso-Betanzos A (2016). A comparison of performance of K-complex classification methods using feature selection. Information Sciences, 328: 1-14. https://doi.org/10.1016/j.ins.2015.08.022 [Google Scholar]
- Hliaoutakis A, Zervanou K, and Petrakis EG (2009). The AMTEx approach in the medical document indexing and retrieval application. Data and Knowledge Engineering, 68(3): 380-392. https://doi.org/10.1016/j.datak.2008.11.002 [Google Scholar]
- Inbarani HH, Bagyamathi M, and Azar AT (2015). A novel hybrid feature selection method based on rough set and improved harmony search. Neural Computing and Applications, 26(8): 1859-1880. https://doi.org/10.1007/s00521-015-1840-0 [Google Scholar]
- Javed K, Babri HA, and Saeed M (2012). Feature selection based on class-dependent densities for high-dimensional binary data. IEEE Transactions on Knowledge and Data Engineering, 24(3): 465-477. https://doi.org/10.1109/TKDE.2010.263 [Google Scholar]
- Joachims T (1997). A probabilistic analysis of the Rocchio algorithm with tf-idf for text categorization. In the 14th International Conference on Machine Learning (ICML’97), Morgan Kaufmann Publishers Inc., Nashville, USA: 143-151. [Google Scholar]
- Kamruzzaman SM, Haider F, and Hasan AR (2005). Text classification using data mining. In the International Conference on Computer and Information Technology, Cyberjaya, Malaysia: 135-139. [Google Scholar]
- Khalid S, Khalil T, and Nasreen S (2014). A survey of feature selection and feature extraction techniques in machine learning. In the Science and Information Conference, IEEE, London, UK: 372-378. https://doi.org/10.1109/SAI.2014.6918213 [Google Scholar]
- Lee C and Lee GG (2006). Information gain and divergence-based feature selection for machine learning-based text categorization. Information Processing and Management, 42(1): 155-165. https://doi.org/10.1016/j.ipm.2004.08.006 [Google Scholar]
- Li Y, Lin H, and Yang Z (2007). Two approaches for biomedical text classification. In the 1st International Conference on Bioinformatics and Biomedical Engineering, IEEE, Wuhan, China: 310-313. https://doi.org/10.1109/ICBBE.2007.83 [Google Scholar]
- Liu H, Sun J, Liu L, and Zhang H (2009). Feature selection with dynamic mutual information. Pattern Recognition, 42(7): 1330-1339. https://doi.org/10.1016/j.patcog.2008.10.028 [Google Scholar]
- Maji P and Paul S (2011). Rough set based maximum relevance-maximum significance criterion and gene selection from microarray data. International Journal of Approximate Reasoning, 52(3): 408-426. https://doi.org/10.1016/j.ijar.2010.09.006 [Google Scholar]
- Maldonado S and Weber R (2009). A wrapper method for feature selection using support vector machines. Information Sciences, 179(13): 2208-2217. https://doi.org/10.1016/j.ins.2009.02.014 [Google Scholar]
- Mendez JR, Cotos-Yañez TR, and Ruano-Ordás D (2019). A new semantic-based feature selection method for spam filtering. Applied Soft Computing, 76: 89-104. https://doi.org/10.1016/j.asoc.2018.12.008 [Google Scholar]
- Mirończuk MM and Protasiewicz J (2018). A recent overview of the state-of-the-art elements of text classification. Expert Systems with Applications, 106: 36-54. https://doi.org/10.1016/j.eswa.2018.03.058 [Google Scholar]
- Ohsumed (2005). DataSet. Available online at: https://bit.ly/2SStkdf
- Pinheiro RH, Cavalcanti GD, and Ren TI (2015). Data-driven global-ranking local feature selection methods for text categorization. Expert Systems with Applications, 42(4): 1941-1949. https://doi.org/10.1016/j.eswa.2014.10.011 [Google Scholar]
- Raza MS and Qamar U (2016). An incremental dependency calculation technique for feature selection using rough sets. Information Sciences, 343: 41-65. https://doi.org/10.1016/j.ins.2016.01.044 [Google Scholar]
- Rehman A, Javed K, Babri HA, and Saeed M (2015). Relative discrimination criterion–A novel feature ranking method for text data. Expert Systems with Applications, 42(7): 3670-3681. https://doi.org/10.1016/j.eswa.2014.12.013 [Google Scholar]
- Rizaldy A and Santoso HA (2017). Performance improvement of support vector machine (SVM) with information gain on categorization of Indonesian news documents. In the International Seminar on Application for Technology of Information and Communication, IEEE, Semarang, Indonesia: 227-232. https://doi.org/10.1109/ISEMANTIC.2017.8251874 [Google Scholar]
- Sabbah T, Selamat A, Selamat MH, Ibrahim R, and Fujita H (2016). Hybridized term-weighting method for dark web classification. Neurocomputing, 173(Part 3): 1908-1926. https://doi.org/10.1016/j.neucom.2015.09.063 [Google Scholar]
- Salton G, Wong A, and Yang CS (1975). A vector space model for automatic indexing. Communications of the ACM, 18(11): 613-620. https://doi.org/10.1145/361219.361220 [Google Scholar]
- Sampson M, de Bruijn B, Urquhart C, and Shojania K (2016). Complementary approaches to searching MEDLINE may be sufficient for updating systematic reviews. Journal of Clinical Epidemiology, 78: 108-115. https://doi.org/10.1016/j.jclinepi.2016.03.004 [Google Scholar] PMid:26976054
- Saqib SM, Kundi FM, Ahmad S, and Naeem T (2019). Automatic classification of product reviews into interrogative and non-interrogative: Generating real time answer. International Journal of Advanced and Applied Sciences, 6(8): 23-31. https://doi.org/10.21833/ijaas.2019.08.004 [Google Scholar]
- Selamat A and Omatu S (2004). Web page feature selection and classification using neural networks. Information Sciences, 158: 69-88. https://doi.org/10.1016/j.ins.2003.03.003 [Google Scholar]
- Tang X, Dai Y, and Xiang Y (2019). Feature selection based on feature interactions with application to text categorization. Expert Systems with Applications, 120: 207-216. https://doi.org/10.1016/j.eswa.2018.11.018 [Google Scholar]
- Thaoroijam K (2014). A study on document classification using machine learning techniques. International Journal of Computer Science Issues, 11(2): 217-222. [Google Scholar]
- Tutkan M, Ganiz MC, and Akyokuş S (2016). Helmholtz principle based supervised and unsupervised feature selection methods for text mining. Information Processing and Management, 52(5): 885-910. https://doi.org/10.1016/j.ipm.2016.03.007 [Google Scholar]
- Uysal AK and Gunal S (2014). The impact of preprocessing on text classification. Information Processing and Management, 50(1): 104-112. https://doi.org/10.1016/j.ipm.2013.08.006 [Google Scholar]
- Vinh NX, Zhou S, Chan J, and Bailey J (2016). Can high-order dependencies improve mutual information based feature selection? Pattern Recognition, 53: 46-58. https://doi.org/10.1016/j.patcog.2015.11.007 [Google Scholar]
- Wang P, Xu B, Xu J, Tian G, Liu CL, and Hao H (2016). Semantic expansion using word embedding clustering and convolutional neural network for improving short text classification. Neurocomputing, 174: 806-814. https://doi.org/10.1016/j.neucom.2015.09.096 [Google Scholar]
- Wei HL and Billings SA (2007). Feature subset selection and ranking for data dimensionality reduction. IEEE Transactions on Pattern Analysis and Machine Intelligence, 29(1): 162-166. https://doi.org/10.1109/TPAMI.2007.250607 [Google Scholar] PMid:17108391
- Yang Y and Pedersen JO (1997). A comparative study on feature selection in text categorization. In the 14th International Conference on Machine Learning, Morgan Kaufmann Publishers Inc., Nashville, USA: 412-420. [Google Scholar]
- Zhang W, Yoshida T, and Tang X (2008). Text classification based on multi-word with support vector machine. Knowledge-Based Systems, 21(8): 879-886. https://doi.org/10.1016/j.knosys.2008.03.044 [Google Scholar]