
International
ADVANCED AND APPLIED SCIENCES
EISSN: 2313-3724, Print ISSN:2313-626X
Frequency: 12
![]()
Volume 6, Issue 10 (October 2019), Pages: 94-102

----------------------------------------------
Original Research Paper
Title: Analysis of latent Dirichlet allocation and non-negative matrix factorization using latent semantic indexing
Author(s): Sheikh Muhammad Saqib 1, *, Shakeel Ahmad 2, Asif Hassan Syed 2, Tariq Naeem 1, Fahad Mazaed Alotaibi 2
Affiliation(s):
1Institute of Computing and Information Technology, Gomal University, Dera Ismail Khan, Pakistan
2Faculty of Computing and Information Technology in Rabigh (FCITR), King Abdul Aziz University (KAU), Jeddah, Saudi Arabia

* Corresponding Author.
 Corresponding author's ORCID profile: https://orcid.org/0000-0002-4647-1698
Corresponding author's ORCID profile: https://orcid.org/0000-0002-4647-1698
Digital Object Identifier:
https://doi.org/10.21833/ijaas.2019.10.015
Abstract:
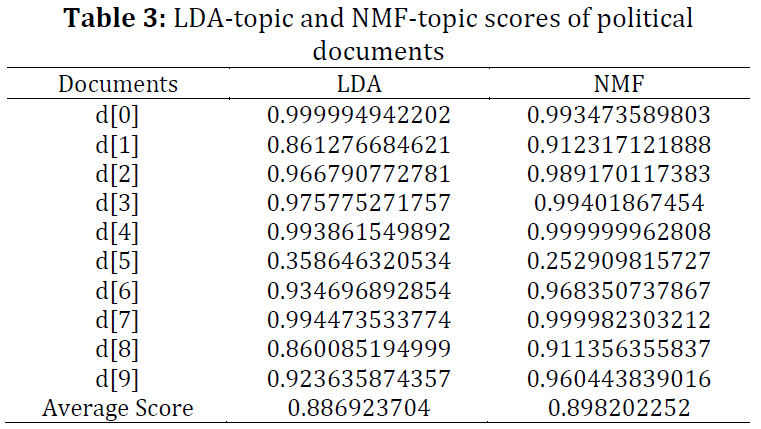
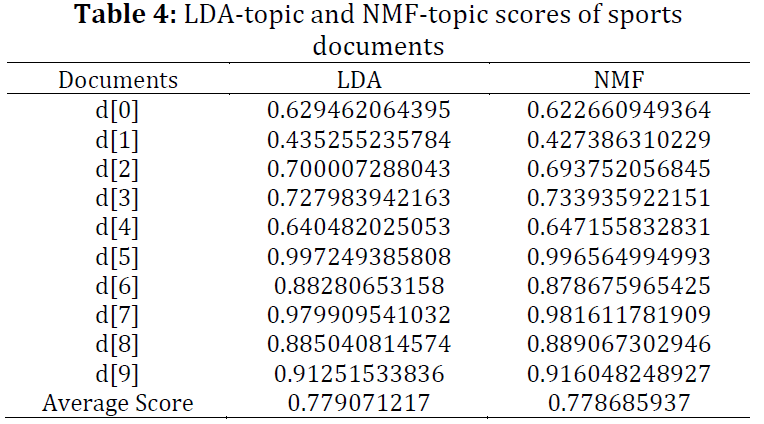
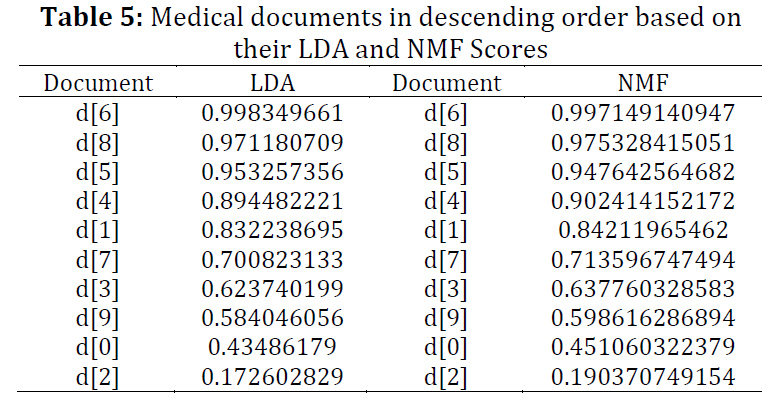
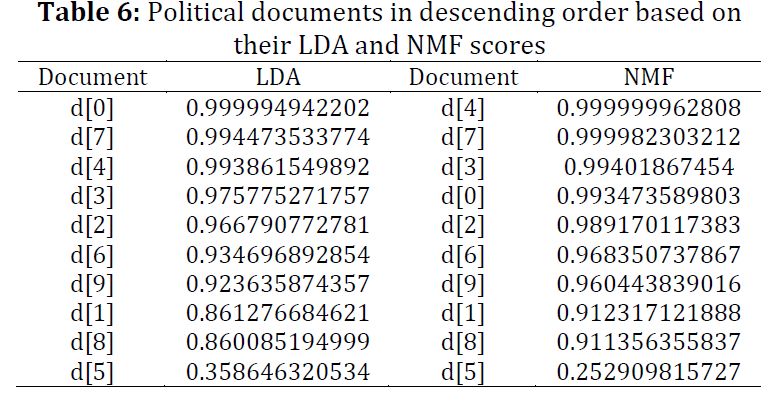
A word is a major attribute in the field of opinion/text mining. Based on this attribute, it is decided that whether it is a keyword, aspect, feature, entity, title, or topic? Lots of work has been done to detect such targets using both supervised and unsupervised approaches. These targets can be used in further processing such as text analytics, sentiment analysis, information retrieval, and searches, etc. Latent Dirichlet allocation (LDA) and non-negative matrix factorization (NMF) are the major models used for detecting topics. Understanding the depth and details of them algorithms are necessary for those who want to extend these models. The research community of opinion/text mining uses them as a black box. However, there is a question about which model is the most accurate for detecting topics. Latent semantic indexing (LSI) is the best approach for detecting the best match for document in a given query. In this study, we analyzed the LDA and NMF models using LSI to determine the best model for opinion/text mining and found that both are very good, but NMF is slightly better than LDA.
© 2019 The Authors. Published by IASE.
This is an
Keywords: Sentiment analysis, Topic modelling, Latent Dirichlet allocation, Non-negative matrix factorization, Latent semantic indexing
Article History: Received 8 May 2019, Received in revised form 15 August 2019, Accepted 16 August 2019
Acknowledgement:
No Acknowledgement.
Compliance with ethical standards
Conflict of interest: The authors declare that they have no conflict of interest.
Citation:
Saqib SM, Ahmad S, and Syed AH et al. (2019). Analysis of latent Dirichlet allocation and non-negative matrix factorization using latent semantic indexing. International Journal of Advanced and Applied Sciences, 6(10): 94-102
Figures
{kind=link}
{kind=link}
{kind=link}
Tables
Table 1 Table 2 Table 3 Table 4 Table 5 Table 6 Table 7
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
----------------------------------------------
References (56)
- Agrawal A, Fu W, and Menzies T (2018). What is wrong with topic modeling? And how to fix it using search-based software engineering. Information and Software Technology, 98: 74-88. https://doi.org/10.1016/j.infsof.2018.02.005 [Google Scholar]
- Alshammari R (2018). Arabic text categorization using machine learning approaches. International Journal of Advanced Computer Science and Applications, 9(3): 226-230. https://doi.org/10.14569/IJACSA.2018.090332 [Google Scholar]
- Awajan AA (2014). Unsupervised approach for automatic keyword extraction from Arabic documents. In the 26th Conference on Computational Linguistics and Speech Processing, The Association for Computational Linguistics and Chinese Language Processing, Jhongli, Taiwan: 175-184. [Google Scholar]
- Blei D, Carin L, and Dunson D (2010). Probabilistic topic models: A focus on graphical model design and applications to document and image analysis. IEEE Signal Processing Magazine, 27(6): 55-65. https://doi.org/10.1109/MSP.2010.938079 [Google Scholar] PMid:25104898 PMCid:PMC4122269
- Blei DM and McAuliffe JD (2010). Supervised topic models. In Proceedings of NIPS, Vancouver, Canada. Available online at: https://bit.ly/2ZAqO0A
- Blei DM, Ng AY, and Jordan MI (2003). Latent Dirichlet allocation. Journal of Machine Learning Research, 3: 993-1022. [Google Scholar]
- Boyd-Graber J and Resnik P (2010). Holistic sentiment analysis across languages: Multilingual supervised latent Dirichlet allocation. In the 2010 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Cambridge, USA: 45-55. [Google Scholar]
- Chawla R (2017). Topic modeling with LDA and NMF on the ABC News headlines dataset. Available online at: https://bit.ly/2MIjpGA
- Chen Y and Filliat D (2015). Cross-situational noun and adjective learning in an interactive scenario. In the 2015 Joint IEEE International Conference on Development and Learning and Epigenetic, IEEE, Providence, USA: 129-134. https://doi.org/10.1109/DEVLRN.2015.7346129 [Google Scholar]
- Chen Y, Bordes JB, and Filliat D (2017). An experimental comparison between NMF and LDA for active cross-situational object-word learning. In the 2016 Joint IEEE International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), IEEE, Cergy-Pontoise, France: 217-222. https://doi.org/10.1109/DEVLRN.2016.7846822 [Google Scholar]
- Chen Y, Rege M, Dong M, and Hua J (2008). Non-negative matrix factorization for semi-supervised data clustering. Knowledge and Information Systems, 17(3): 355-379. https://doi.org/10.1007/s10115-008-0134-6 [Google Scholar]
- Chinsha TC and Joseph S (2015). A syntactic approach for aspect based opinion mining. In the 2015 IEEE 9th International Conference on Semantic Computing, IEEE, Anaheim, USA: 24-31. https://doi.org/10.1109/ICOSC.2015.7050774 [Google Scholar]
- Deerwester S, Dumais ST, Furnas GW, Landauer TK, and Harshman R (1990). Indexing by latent semantic analysis. Journal of the American Society for Information Science, 41(6): 391-407. https://doi.org/10.1002/(SICI)1097-4571(199009)41:6<391::AID-ASI1>3.0.CO;2-9 [Google Scholar]
- El-Fishawy N, Hamouda A, Attiya GM, and Atef M (2014). Arabic summarization in twitter social network. Ain Shams Engineering Journal, 5(2): 411-420. https://doi.org/10.1016/j.asej.2013.11.002 [Google Scholar]
- Gamon M, Aue A, Corston-Oliver S, and Ringger E (2005). Pulse: Mining customer opinions from free text. In the International Symposium on Intelligent Data Analysis, Springer, Hertogenbosch, Netherlands: 121-132. https://doi.org/10.1007/11552253_12 [Google Scholar]
- Gao S and Li H (2011). A cross-domain adaptation method for sentiment classification using probabilistic latent analysis. In the 20th ACM International Conference on Information and Knowledge Management, ACM, Glasgow, Scotland: 1047-1052. https://doi.org/10.1145/2063576.2063728 [Google Scholar]
- Gindl S, Weichselbraun A, and Scharl A (2013). Rule-based opinion target and aspect extraction to acquire affective knowledge. In the 22nd International Conference on World Wide Web, ACM, Rio de Janeiro, Brazil: 557-564. https://doi.org/10.1145/2487788.2487994 [Google Scholar]
- Gojali S and Khodra ML (2016). Aspect based sentiment analysis for review rating prediction. In the 2016 International Conference on Advanced Informatics: Concepts, Theory and Application, IEEE, George Town, Malaysia: 1-6. https://doi.org/10.1109/ICAICTA.2016.7803110 [Google Scholar]
- Guo H, Zhu H, Guo Z, Zhang X, and Su Z (2009). Product feature categorization with multilevel latent semantic association. In the 18th ACM Conference on Information and Knowledge Management, ACM, Hong Kong, China: 1087-1096. https://doi.org/10.1145/1645953.1646091 [Google Scholar] PMid:19757454
- Gupta DK and Ekbal A (2014). IITP: Supervised machine learning for aspect based sentiment analysis. In the 8th International Workshop on Semantic Evaluation, Dublin, Ireland: 319-323. https://doi.org/10.3115/v1/S14-2053 [Google Scholar]
- He Y, Lin C, and Alani H (2011). Automatically extracting polarity-bearing topics for cross-domain sentiment classification. In the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics, Portland, USA, 1: 123-131. [Google Scholar]
- Hu M and Liu B (2004). Mining and summarizing customer reviews. In the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, Seattle, USA: 168-177. https://doi.org/10.1145/1014052.1014073 [Google Scholar]
- Huang A, Milne D, Frank E, and Witten IH (2009). Clustering documents using a Wikipedia-based concept representation. In the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Springer, Macau, China: 628-636. https://doi.org/10.1007/978-3-642-01307-2_62 [Google Scholar]
- Jeyapriya A and Selvi CK (2015). Extracting aspects and mining opinions in product reviews using supervised learning algorithm. In the 2015 2nd International Conference on Electronics and Communication Systems, IEEE, Coimbatore, India: 548-552. https://doi.org/10.1109/ECS.2015.7124967 [Google Scholar]
- Jo Y and Oh AH (2011). Aspect and sentiment unification model for online review analysis. In the 4th ACM International Conference on Web Search and Data Mining, ACM, Hong Kong, China: 815-824. https://doi.org/10.1145/1935826.1935932 [Google Scholar]
- Leek T, Jin H, Sista S, and Schwartz R (2000). The BBN cross lingual topic detection and tracking system. In The Working Notes of the Third Topic Detection and Tracking Workshop, BBN Technologies, Cambridge, USA. [Google Scholar]
- Li S, Lee SYM, Chen Y, Huang CR, and Zhou G (2010). Sentiment classification and polarity shifting. In the 23rd International Conference on Computational Linguistics, Association for Computational Linguistics, Beijing, China: 635-643. [Google Scholar]
- Lin C and He Y (2009). Joint sentiment/topic model for sentiment analysis. In the 18th ACM Conference on Information and Knowledge Management, ACM, Hong Kong, China: 375-384. https://doi.org/10.1145/1645953.1646003 [Google Scholar] PMCid:PMC2779244
- Liu H and Wu Z (2010). Non-negative matrix factorization with constraints. In the 24th AAAI Conference on Artificial Intelligence, AAAI Press, Atlanta, USA: 506–511. [Google Scholar]
- Lu Y, Zhai C, and Sundaresan N (2009). Rated aspect summarization of short comments. In the 18th International Conference on World Wide Web, ACM, Madrid, Spain: 131-140. https://doi.org/10.1145/1526709.1526728 [Google Scholar] PMCid:PMC3280738
- MacMillan K and Wilson JD (2017). Topic supervised non-negative matrix factorization. Available online at: https://bit.ly/30I6WWM
- Mangin O, Filliat D, Ten Bosch L, and Oudeyer PY (2015). MCA-NMF: Multimodal concept acquisition with non-negative matrix factorization. PloS One, 10(10): e0140732. https://doi.org/10.1371/journal.pone.0140732 [Google Scholar] PMid:26489021 PMCid:PMC4619362
- Mei Q, Ling X, Wondra M, Su H, and Zhai C (2007). Topic sentiment mixture: Modeling facets and opinions in weblogs. In the 16th International Conference on World Wide Web, ACM, Banff, Alberta, Canada: 171-180. https://doi.org/10.1145/1242572.1242596 [Google Scholar] PMid:17825604
- Moghaddam S and Ester M (2011). ILDA: Interdependent LDA model for learning latent aspects and their ratings from online product reviews. In the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, ACM, Beijing, China: 665-674. https://doi.org/10.1145/2009916.2010006 [Google Scholar]
- Mukherjee A and Liu B (2012). Aspect extraction through semi-supervised modeling. In the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers, Association for Computational Linguistics, Jeju Island, South Korea, 1: 339-348. [Google Scholar]
- Pang B and Lee L (2008). Opinion mining and sentiment analysis. Foundations and Trends® in Information Retrieval, 2(1–2): 1-135. https://doi.org/10.1561/1500000011 [Google Scholar]
- Pantel P, Crestan E, Borkovsky A, Popescu AM, and Vyas V (2009). Web-scale distributional similarity and entity set expansion. In the 2009 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Singapore, Singapore, 2: 938-947. https://doi.org/10.3115/1699571.1699635 [Google Scholar]
- Peng W and Park DH (2011). Generate adjective sentiment dictionary for social media sentiment analysis using constrained nonnegative matrix factorization. In the 50th International AAAI Conference on Weblogs and Social Media, Barcelona, Spain: 273-280. [Google Scholar]
- Phadnis N and Gadge J (2014). Framework for document retrieval using latent semantic indexing. International Journal of Computer Applications, 94(14): 37-41. https://doi.org/10.5120/16414-6065 [Google Scholar]
- Qi L and Chen L (2011). Comparison of model-based learning methods for feature-level opinion mining. In the 2011 International Conferences on Web Intelligence and Intelligent Agent Technology, IEEE Computer Society, Washington, USA, 1: 265-273. https://doi.org/10.1109/WI-IAT.2011.64 [Google Scholar]
- Raganato A, Camacho-Collados J, and Navigli R (2017). Word sense disambiguation: A unified evaluation framework and empirical comparison. In the 15th Conference of the European Chapter of the Association for Computational Linguistics, Association for Computational Linguistics, Valencia, Spain, 1: 99-110. https://doi.org/10.18653/v1/E17-1010 [Google Scholar]
- Rammal M, Bahsoun Z, and Al Achkar Jabbour M (2015). Keyword extraction from Arabic legal texts. Interactive Technology and Smart Education, 12(1): 62-71. https://doi.org/10.1108/ITSE-11-2013-0030 [Google Scholar]
- Rose S, Engel D, Cramer N, and Cowley W (2010). Automatic keyword extraction from individual documents. In: Berry MW and Kogan J (Eds.), Text mining: Applications and theory: 1-20. John Wiley and Sons, Hoboken, USA. https://doi.org/10.1002/9780470689646.ch1 [Google Scholar]
- Saqib SM, Mahmood K, and Naeem T (2016). Comparison of LSI algorithms without and with pre-processing: Using text document based search. ACCENTS Transactions on Information Security, 1(4): 44–51. [Google Scholar]
- Sauper C, Haghighi A, and Barzilay R (2011). Content models with attitude. In the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics, Portland, USA, 1: 350-358. [Google Scholar]
- Stevens K, Kegelmeyer P, Andrzejewski D, and Buttler D (2012). Exploring topic coherence over many models and many topics. In the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Association for Computational Linguistics, Jeju Island, South Korea: 952-961. [Google Scholar]
- Suri P and Roy NR (2017). Comparison between LDA & NMF for event-detection from large text stream data. In the 2017 3rd International Conference on Computational Intelligence and Communication Technology (CICT), IEEE, Ghaziabad, India: 1-5. https://doi.org/10.1109/CIACT.2017.7977281 [Google Scholar] PMid:30241224
- Taniguchi T, Yoshino R, and Takano T (2018). Multimodal hierarchical Dirichlet process-based active perception by a robot. Frontiers in Neurorobotics, 12: 22. https://doi.org/10.3389/fnbot.2018.00022 [Google Scholar] PMid:29872389 PMCid:PMC5972223
- Thakur D and Singh J (2015). The SAFE miner: A fine grained aspect level approach for resolving the sentiment. In the 2015 3rd International Conference on Computer, Communication, Control and Information Technology, IEEE, Hooghly, India: 1-6. https://doi.org/10.1109/C3IT.2015.7060151 [Google Scholar]
- Tumasjan A, Sprenger TO, Sandner PG, and Welpe IM (2010). Predicting elections with twitter: What 140 characters' reveal about political sentiment. In the 4th International AAAI Conference on Weblogs and Social Media, Association for the Advancement of Artificial Intelligence, Washington, USA: 178-185. [Google Scholar]
- Wang SH, Ding Y, Zhao W, Huang YH, Perkins R, Zou W, and Chen JJ (2016). Text mining for identifying topics in the literatures about adolescent substance use and depression. BMC Public Health, 16: 279. https://doi.org/10.1186/s12889-016-2932-1 [Google Scholar] PMid:26993983 PMCid:PMC4799597
- Xue Y, Tong CS, and Yuan JY (2014). LDA-based non-negative matrix factorization for supervised face recognition. Journal of Software, 9(5): 1294-1301. https://doi.org/10.4304/jsw.9.5.1294-1301 [Google Scholar]
- Yang Q and Li FM (2005). Support vector machine for customized email filtering based on improving latent semantic indexing. In the 2005 International Conference on Machine Learning and Cybernetics, IEEE, Guangzhou, China, 6: 3787-3791. https://doi.org/10.1109/ICMLC.2005.1527599 [Google Scholar]
- Zhai Z, Liu B, Xu H, and Jia P (2011). Clustering product features for opinion mining. In the 4th ACM International Conference on Web Search and Data Mining, ACM, Hong Kong, China: 347-354. https://doi.org/10.1145/1935826.1935884 [Google Scholar]
- Zhao WX, Jiang J, Yan H, and Li X (2010). Jointly modeling aspects and opinions with a MaxEnt-LDA hybrid. In the 2010 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Cambridge, USA: 56-65. [Google Scholar]
- Zhuang L, Jing F, and Zhu XY (2006). Movie review mining and summarization. In the 15th ACM International Conference on Information and Knowledge Management, ACM, Arlington, USA: 43-50. https://doi.org/10.1145/1183614.1183625 [Google Scholar]